在R系统中我们不需要知道tuple的物理储存和访问路径是否合适,也无需知道join的具体执行顺序如何,在join order和access path的选择中,我们可以选择能够最小化total access cost的任务来执行整个访问
Processing of an SQL statement
sql statement 执行分为四步:
- parsing
- optimization
- code generation
- execution
第一步首先检查语法正确性
一个单一的sql语句可能有多个query block组成,因为每个谓词的操作数都可能有一个query
每个query block由select list,FROM list, WHERE tree表示,每一部分都有待检索的实体,被引用的表,和布尔表达式。
parser任务完成后来到optimzer,optimizer收集query中引用的表和列,通过catalog 确认存在并去检索相关信息.
catalog检索部分同时也要获取引用关系的统计和合适的访问路径,以便于访问路径选择,最后要在表达式和谓词比较中检查语义错误和类型兼容
最后optimzer要执行访问路径选择,它首先确定query block的执行顺序,对于每一个query block,处理From list中的关系,如果在一个查询块中存在多个关系,则对不同的join的执行顺序和执行方法进行评估,已进行选择
访问路径的最优解从由不同路径选择构成的树上进行选择
最优解由对parse tree进行结构化修改获得
确定好query plan后,并且将其在parse tree中表示后,调用code generator,在code generation过程中,parse tree被可执行的机器码和对应的数据结构代替。生成的代码最终被执行时,他通过存储系统借口(RSI)调用存储系统(RSS)
The Research Storage System
存储结构: tuple ->page->segment 我们通过scan访问tuple
一种是segment scan,访问所有segnment上的tuple去找满足条件的tuple,所有tuple都会被访问一次
第二种是index scan,通过索引访问tuple,有可能造成重复访问,采用clustered index会好一点论文结构图
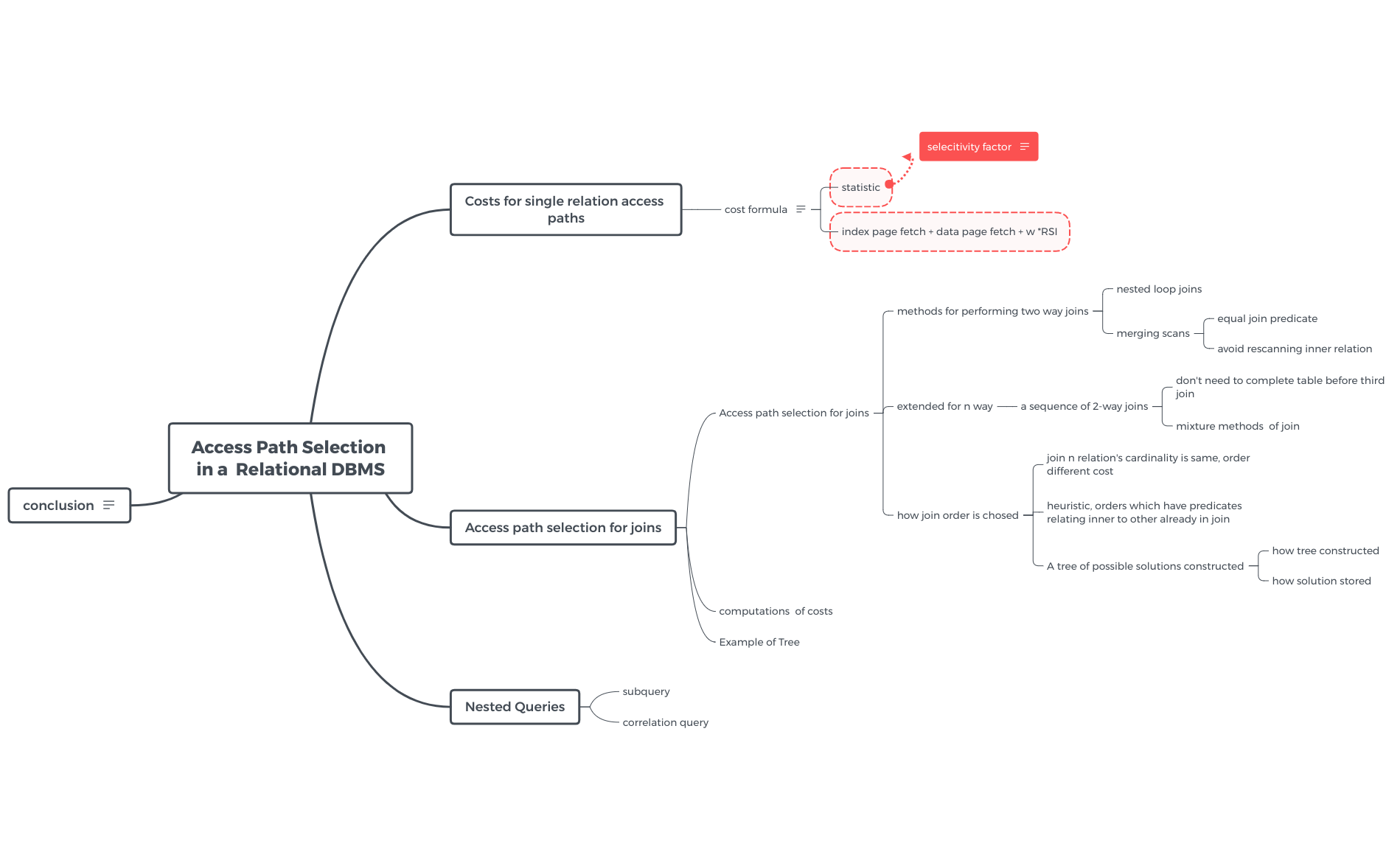
Cost for single relation access paths
由于是对访问路径进行最优解选择,需要提供cost模型,考虑disk io和cpu utilization
可用如下公式表示:
cost = page feteches + w * rsi calls 如何利用此公式对 single query 进行量化呢,首先考虑page fetch:
一个single query block由select from where构成,问题的核心在于由where导致的条件所要搜索的tuple数目
我们在catalog中进行基本的数据统计,并同时得到一个selectivity factor,表示相关谓词中满足条件的tuple的占比
最终得到俩个结果:
QCARD: query cardinality 每一个query中from relation list的 cardinality乘以where中query factor的selectivity factor
RSICARD: relation cardinality 乘以 sarg 的selectivity factor
假设query中有ordered by 或者 group by 时,有nteresting order的概念,此时我们需要将最便宜的interesting order和unordered find加上sorting进行比较
对于single relation access, cost公式具体表示为index page fetch + data page fetch + W * RSI retrieval calls
此处需要考虑buffer的影响
Access path selection for joins
我们要首先决定join的执行过程,再将其衍生到n-way join, 再根据join的执行过程计算cost模型,进行选择
join的方法有俩种,第一种: nested-loop join: 分为outer join 和 inner join.采用类似于俩个for loop的方式执行,且对顺序没有要求
第二种叫做merging scan:
该方法要求outer 和 inner relation按照join column order进行scan,
同时我们还可以利用join column 的ordering避免rescanning inner
对于n-way join,我们可以将其看做一系列的2-way join。
接下来考虑join order 的问题:
对于from list中n个 relation,会有n!个join顺序,前k 后 n-k 具有独立性
我们只选择由join predicate的,连接inner join 和正在参与的join. 即先选择有join relation的join,后选择没有的join。
构造search tree
computation for costs
如何计算join 的costs 此处注意的点:
- 计算根据outer和inner将cost 分为c-outer和c-inner,注意nested-loop和merge-join中 C_inner计算方式的不同
- 注意merge为何优于inner-loop
Example of a Tree
理解原论文中的树和merge join中 sort的作用,另一种选择
nested queries
从内到外开始展开