introduction: lock的缺点
- 维护lock会造成overhead, 例如read操作不会破坏数据的一致性,也要因为防止read过程中其他txn改变数据而加锁,同时不是deadlock-free的lock会造成deadlock相关的操作
- 没有通用的deadlock-free 并发机制,所以deadlock造成的损失一定会存在
- 涉及到secondary memory的时候,如果txn在访问sencondary memory的时候同时使congested node lock的话会降低并发性
- 为了满足abort,lock往往要在transaction完成时释放,,也会降低并发性
- lock往往适用于最坏的情况
我们转换思路,采用一种不需要lock的方式来保持并发,基本思路如下: - read不需要限制
- 一个transaction包含三部分, read phase, validation phase,和write phase, read phase过程中所有的对数据的更新都发生在备份上,在validation phase,我们判断数据更新是否会造成不一致性,然后write phase 将其global
THE READ AND WRITE PHASES
所需要的基础api: creat, delete(n), read(n, i), write(n, i, v), copy(n), exchange(n1, n2).
在transaction执行过程中,tbegin将相关的set初始化, 而tend则开始validation和write部分
在read过程中,进行的读写操作如下:

 简而言之就是read phase过程中的write都发生在副本上,不可以被其他的transaction访问
简而言之就是read phase过程中的write都发生在副本上,不可以被其他的transaction访问
在write phase中我们要做的就是使write global,同时做一些clean up:
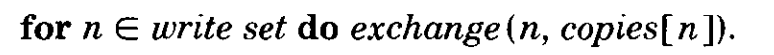
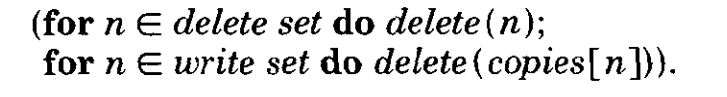
the validation phase
并发执行的正确性可以通过serial equalvalence确定,简而言之就是txn的并发执行等同于某种顺序的线性执行
Validation of serial equaivalence
为了确定 concurrecy的serial equaivalence,我们必须要确定一种transaction的排列,我们为transaction T_i提供一个transaction number, t(i),当t1 < tj是, T_i 在T_j之前发生,当并发执行中以下三种情况满足时,该情况满足:
- Ti要在Tj 开始read phase之前开始write phase
- Ti的write set和Tj的read set没有交集,同时Ti要先完成write phase 在Tj开始write phase之前
- Ti的write set和Tj的read set 和write set没有交集,且Ti的read要在Tj的read完成之前完成
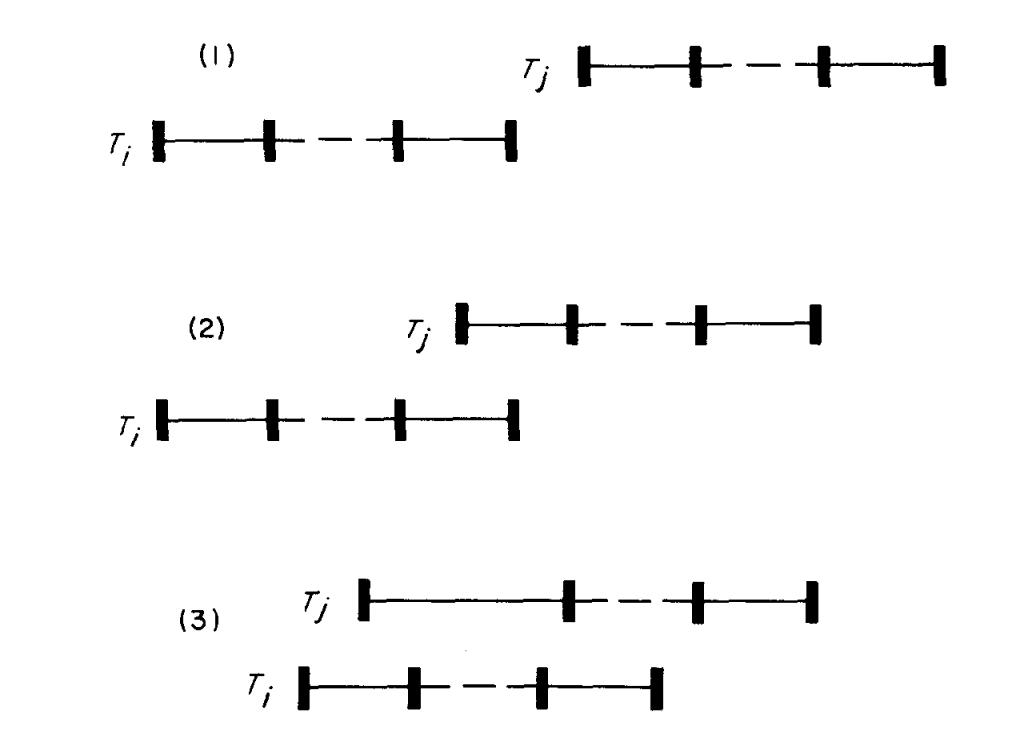
Assigning Transaction Numbers
transaction number的分配: 是一个无限增长的数字分配给各个transaction, 要在transaction read phase 完成后在分配;
要在validation phase开始前分配,因为validation phase需要一部分 transaction number的知识
为何不在read phase开始前分配:
假设俩个几乎同时开始的transaction被分配了t1, t2俩个number,如果T2在T1之前完成了read phase,T2的validation phase 必须要等待T1read phase的完成,因为T2的validation phase要利用T1 write set的知识,所以要在read phase 完成后分配Some pratical Considerations
如果一个transaction read phase 是任意长的话,那么在他开始validation的时候它会需要无限多的以前未开始write phase的transaction的write set的信息,这是不可能的,因为我们无法保存无限多的write set info.解决方式: 保存最近的n个write set的info。 如果n足够大的话,这个问题就可以被有效解决
另一个需要考虑的问题:
如果validation fail的情况怎么考虑:
validation失败,transaction abort, 重启,并赋予新的txn number.
如果transaction连续失败的话:
重启,但不释放critical section的semaphore, 然后starving transaction将会完成Seiral validation
我们考虑实现上述情况的1和2,由于2最后表示所有的写必须是线性的,我们通过将transaction number的赋值, validation和wrte phase都放置在critical region中,critical region是 OS概念.
我们将critical region放置在<>之中,最终实现如下:
 上述情况更适合一个cpu并且write phase发生在主存中,如果write phase不能在主存中进行,我们需要concurrent write phase.
上述情况更适合一个cpu并且write phase发生在主存中,如果write phase不能在主存中进行,我们需要concurrent write phase.
如果有多个cpu,我们要考虑并行性:可以采取如下算法:
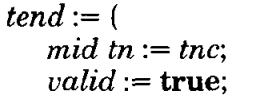
 思路如下:将validation过程分为在critical region 和不在critical region中,并行执行
思路如下:将validation过程分为在critical region 和不在critical region中,并行执行
对于read-only transaction的解决: - 不需要给予 transaction number
- validation过程不需要发生在critical region
parallel validation
我们提供一种并发控制来使用三种validation情况,对于第三种情况,我们维护一个set来保持那些read完成但是还没有完成write的transaction。

 会出现的问题:
会出现的问题:
当前的transaction有可能会被在active set中的某个invalidate的txn invalidate. 解决方式:采用多个阶段的validation步骤,用这种方式减少进入active set的transaction数量