Overview
DBMS的数据模型是record的集合,也可以抽象为file的集合,file由page组成。
file organization指的是如何安排file上的record,当file存储在磁盘上时,我们可以以一定顺序去排以便于检索,但这样做的代价十分昂贵,同时由于操作的多样性,一种排法无法满足所有需求。
我们引入了indexing的技术来辅助我们进行管理。
外部磁盘的内存
磁盘和内存通过页为单元交换信息。磁盘io成为主要负担,优化io是重要任务。我们注意以下几点:
- 连续访问代价远小于随机访问。
- 可通过rid来找对应record存放的page。
file and access layer通过buffer manager访问磁盘
磁盘的空间通过disk access manager来访问.
文件组织和索引
最简单的文件组织是unordered file或者heap file。 index用来组织磁盘上的data records来优化特定类型的retrieval operations。
我们可以利用index的search key来满足检索,我们还可以定义额外的index来满足不同的检索需要。
data entry 是 index file中存储的record,k*代表以k为搜索键值的data entry,我们可以有效的通过键值检索data entry
] 有三种选择用来表示index中的data entry:
- 是实际的数据记录,拥有键值, primary index,数据不可有重复
- 是一个(k, rid)pair
- 是一个(k, rid-list) pair
2, 3 是secondary index,可有重复
1可以直接被当做一种文件存储形式
2.3 可以使目录结构独立于文件组织,3提供了更好的空间利用但是会使data entry处于变量的长度
Clustered Indexes
如果data record 的顺序和data entry的顺序相近或一样时,则称为index 是clustered, 1天然是clustered indexes, 2,3只有在data record基于search key排序时才是clustered
clustered index有着类似于连续存储的特点,这使得它读写代价较小
Index Data structures
Hash-Based Indexing
文件中的records以bucket的形式聚集在一起,一个bucket由一个primary page,有可能由additional page连接起来,哪个record属于哪个bucket由hash function和search key决定。
其具体结构如图所示:
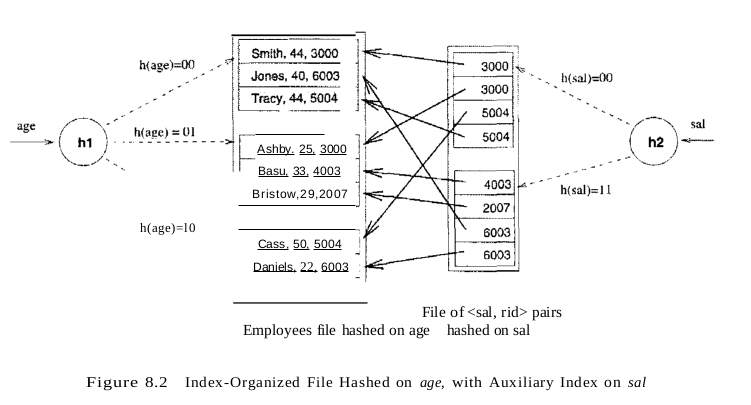 左侧是基于age的hash,其index 结构是第1类型的,右侧是第二类型的,先基于sal的hash找到相关rid,在找到相关record
左侧是基于age的hash,其index 结构是第1类型的,右侧是第二类型的,先基于sal的hash找到相关rid,在找到相关record
Tree-Based Indexing
data entry 以根据search key 排序的方式被组织,然后一个层次型的搜索结构被维护用来指向对应entry的页.
其具体结构如图;
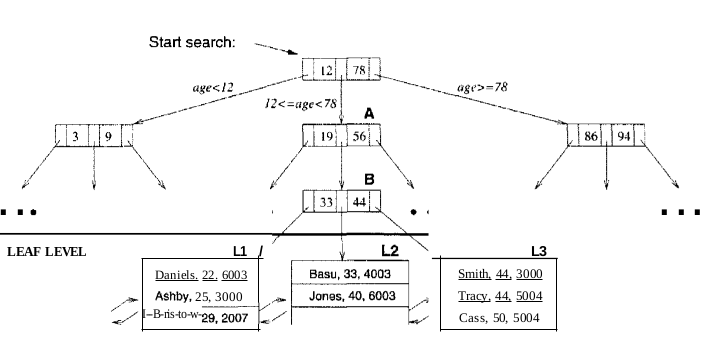 每一个结点都是一个页,检索一个页涉及到disk I/O.中间结点的页包含指向下一个层结点的指针,叶子节点包含data entry,在图中为data record
每一个结点都是一个页,检索一个页涉及到disk I/O.中间结点的页包含指向下一个层结点的指针,叶子节点包含data entry,在图中为data record
每一次检索的disk io数等于从root 到leaf的path长,通过b+树我们可以让路径一样长,
不同文件组织的比较
要考虑的文件类型:
- randomly odered records, heap file
- ordered file
- clustered B+ tree file with search key
- Heap file with unclustered B+ tree
- Heap file with an unclustered hash index
要考虑的操作: scan, search, search with equality, search with range, insert, delete
cost model
B表示page的数目,R表示每一页的record数目,D表示disk io的时间,C表示处理record的时间, H表示应用hash的时间,F表示树的平均子节点,fan-out
Heap File
- scan: B(D+RC)
- search with Equality Selection: 平均情况:0.5B(D+RC)
- search with range: B(D+RC)
- nsert :2D+C, 取出page, 处理, 存
- delete: D+C+ searching
Sorted File
- search :采用二分法搜索: DlogB+ ClogR