介绍
一种方式用来进行敏感分析是attribute grammar,或者attributed-free grammar
attribute grammar 由上下文无关文法增加了一系列指定计算的rule.
每个rule定义了值或者attribute.依据其他属性的值
rule将属性和语法标记联系起来,语法树上每一个语法标志的实例都有一个对应属性的实例
实例:  这是一个符号数的上下文无关文法.
这是一个符号数的上下文无关文法.
为了基于此建立attriute grammar,我们必须决定每个结点需要的性质,同时要精心打造与产生式对应的规则,这些规则为属性定义值。
定义结果如图:
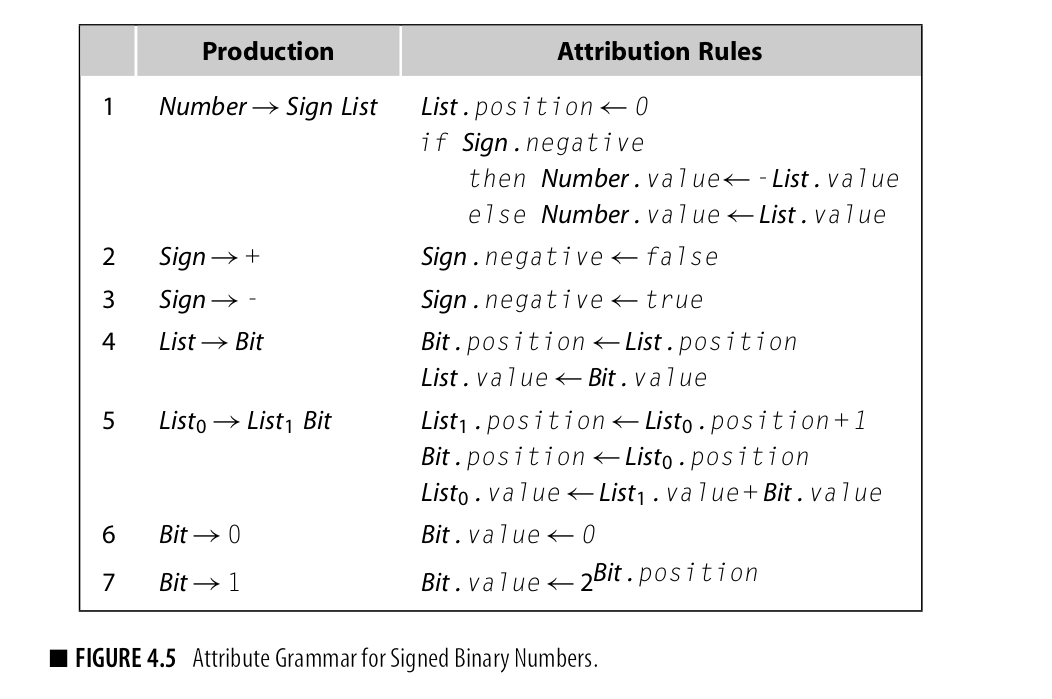
由图可知,每个rule定义了一个属性的值基于常量和其他符号的属性值
rule可从左至右或由右至左的传递信息.
输入一个二进制的string,最终会产生一个annoted parse tree.如下图所示:
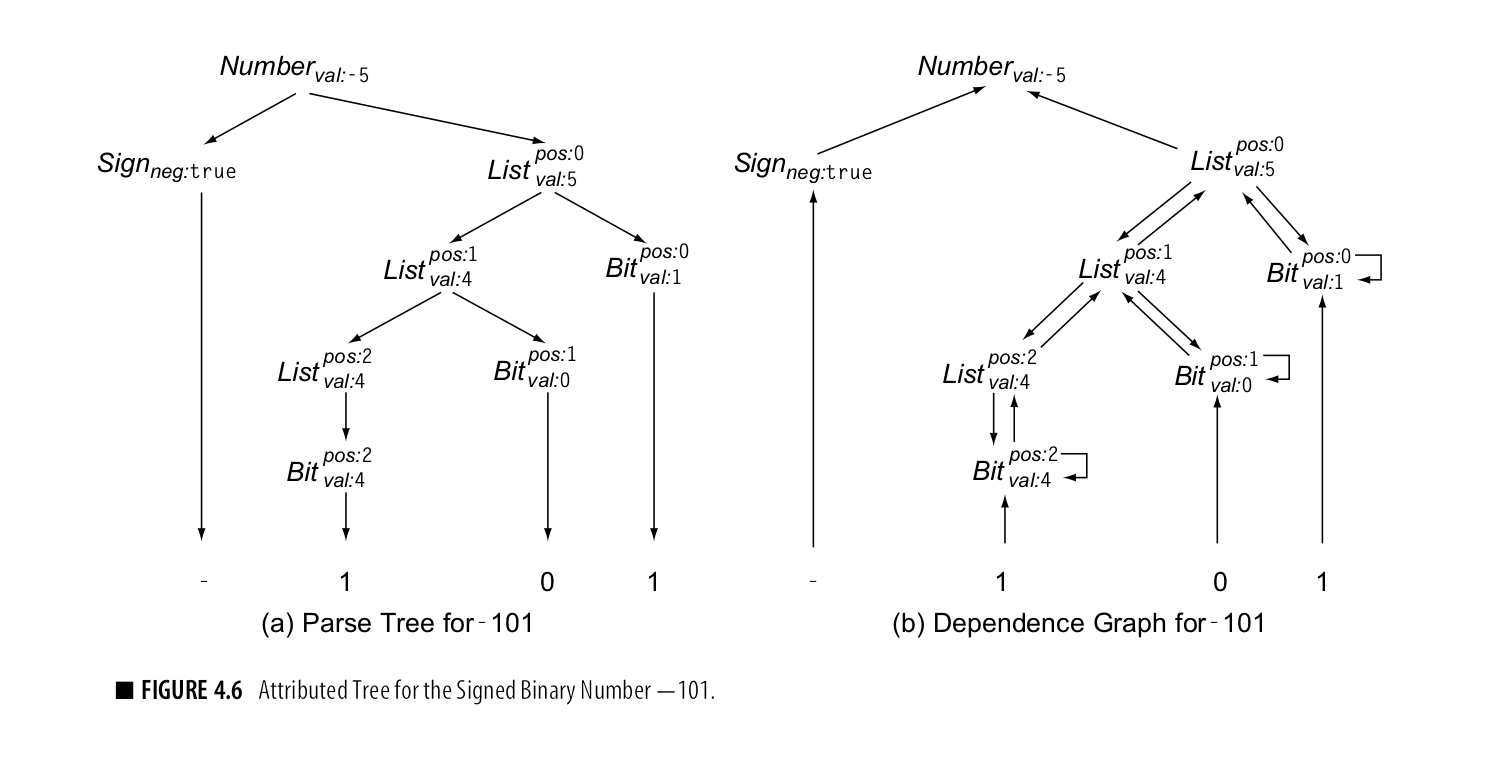 图左侧是注解解析树,右侧是规则依赖图。
图左侧是注解解析树,右侧是规则依赖图。
合成属性是由其叶子结点和常量由下而上定义的属性
继承属性是由其父节点,兄弟结点,自身结点属性定义的属性。
关系依赖图捕获了数据的流动,形成了偏序图(if noncircular),最终属性的计算顺序依赖于该偏序,计算顺序不依赖于其在grammar中的顺序。
为了完成对确定parse tree的计算,必须去构造evaluator.
我们可以通过evaluator generator构造,evaluator generator将attribute grammar的规则指定为输入,产出evaluator代码作为输出,这也是attribute grammar的好处,工具以高级别,非程序的规范作为输入,并且自动产出实现。
atribute-grammar至关重要的一点在于attribute rules可以和上下文无关文法的产生式联系起来,同时rule是函数式的,他们最终的计算结果无关于计算过程。
Evaluation Methods
许多属性计算技巧主要分为三类:
1. Dynamic methods
这种技术依赖于atttributed parse tree.高德纳的论文里在每个rule的操作数都是可用的以后可迅速计算rule.
实践中可以采用队列实现
我们还可以建立属性依赖图,拓扑排序,使用拓扑顺序计算属性
2. Oblivious Methods
系统的设计者选择一种被认为适合于属性语法和评估环境的方法。计算顺序独立于attribute grammar 和 解析树。
方法有从左到右遍历,自上而下遍历,混合遍历。
这些方法实现简单,运行负荷小,但无法从树中学到信息来提高性能.
3. Rule-Baesd Methods
Circularity
前文所述的依赖图有可能出现环,解决方法;
- avoidance 通过限制attribute grammar在一个类中,该类无法产生环,例如只允许合成属性和常数属性,更为通用: strongly noncircular attribute grammars.
- Evaluation会给环中的属性一个合适的值。
Extended Examples
俩个例子:
- 为表达式树推断类型
- 计算执行时间
1. Inferring Expression Types
推断表达式问题基于上下文敏感的信息,和其本体,textual name相关联类型,而不是其语法类型
考虑 一个公式: a - 2 * c, 其生成解析树,解析树的每一个节点都有类型属性,我们需要一个函数能够将操作数和结构的类型映射起来:
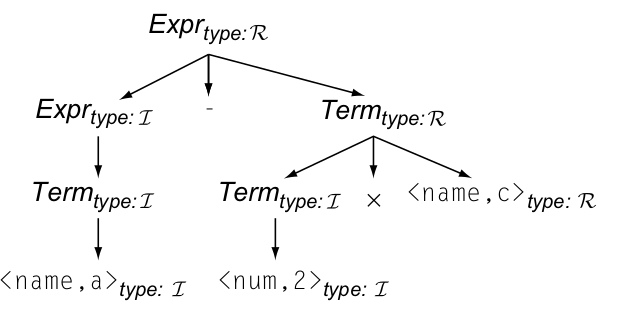 函数映射如下图所示:
函数映射如下图所示:
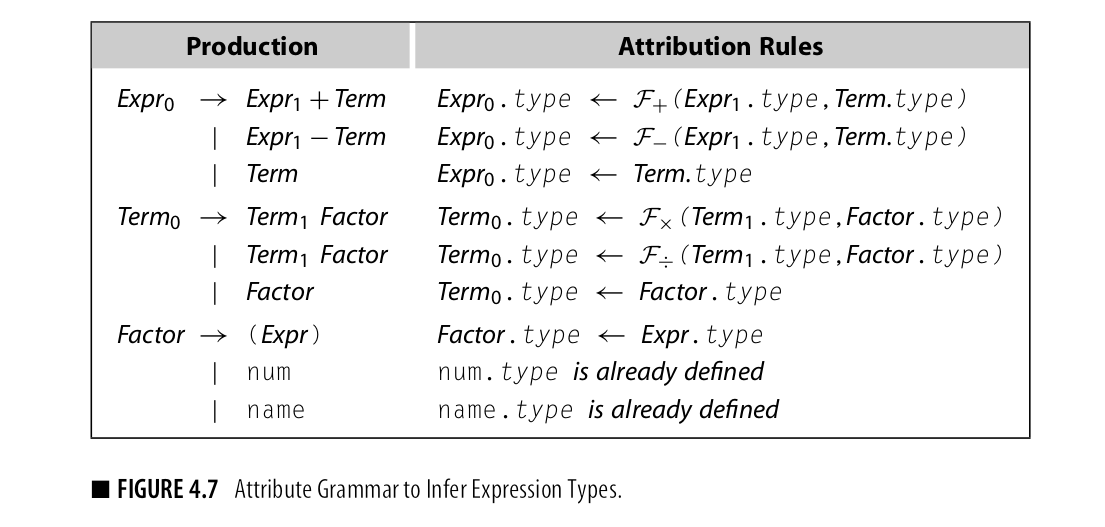 观察上述规则 发现所有属性都是合成属性,所有依赖都由子节点流向父结点,这些语法被称为S-attributed grammars,
观察上述规则 发现所有属性都是合成属性,所有依赖都由子节点流向父结点,这些语法被称为S-attributed grammars,
他与自底向上解析配合非常好,每一个规则都能得出,当Parser有右侧合并为左侧时,
当观察 a - 2 *c时,我们发现 会对部分操作数进行转换,例如转换2的类型和a的类型,如果直接改变类型不满足attribute-grammar的范式,每个rule都是确定函数式的,如果因为其他操作数的类型而对他的类型在进行改变,则是会导致不确定性
我们可以为每一个结点添加新的属性,如converted type,和相应规则,另一种方法我们在生成代码的时候对父子进行比较,加入转换
前者增加attribute evaluation的负担,但将步骤限制在该环节, 后者延后了工作,但增加了将相关类型信息分布在编译器俩部分的代价
2. A simple Execution-Time Estimator
考虑一系列assignment的执行时间,先在原有基础上加入assignment相关production,在attribute rules上添加cost的attribute并添加相关规则
其过程如图所示:
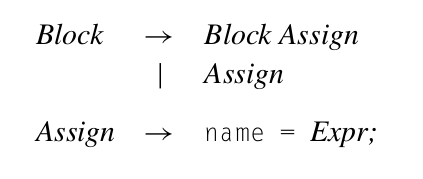
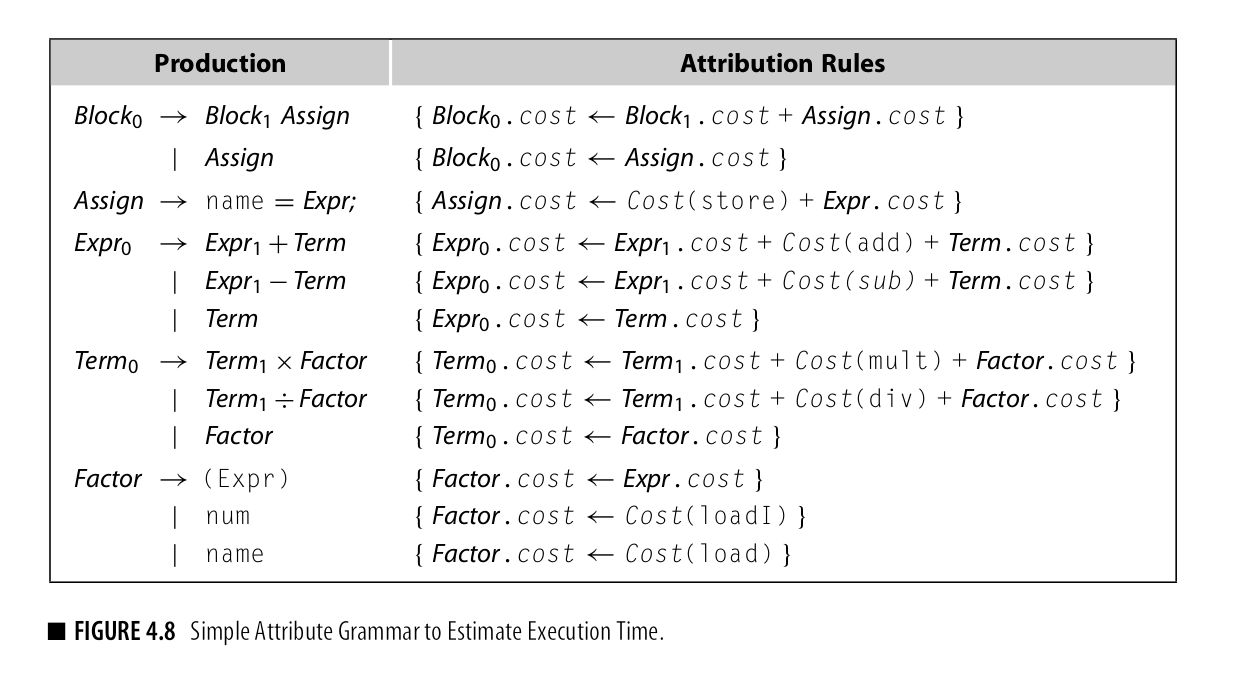
Improving the Execution-Cost Estimator
提升上一个模型的方式:考虑编译器如何处理变量
最初的attribute-grammar假定编译器为每个指向变量的引用做load操作,例如对于x = y + y,最初模型会认为每个y都有load操作,实际并不如此
为了更好的模拟真实编译器的行为,attribute grammar对每一个变量只使用一次load.
由于在parse tree中,我们只有语法类型,没有实际的name,我们需要添加和name相关的属性,同时针对name的规则如下:
 为了实现该规则,我们要添加属性能够维护所有已经加载的变量,而这个集合还要在解析树上随着表达式传递,因此,我们需要在每个结点添加俩个集合
为了实现该规则,我们要添加属性能够维护所有已经加载的变量,而这个集合还要在解析树上随着表达式传递,因此,我们需要在每个结点添加俩个集合
before集合在对应代码块之前出现的name,这些name已经loaded,而after集合,则表示所有出现在before的name加上以该node为结点的子树的结点
举例如下:
 我们采用copy rule来使集合在解析树上流动
我们采用copy rule来使集合在解析树上流动
这种方法动用了很多规则,不仅有合成属性,还有继承属性,很难用普通的自底向上计算,同时相关的操作需要十分小心
对于推导表达式类型的补充
如何补完解析树上结点的类型呢?
我们同样需要构造规则,这些规则需要记录有声明的变量的类型,同时对于信息需要收集和集合,以使较小的集合满足所有声明的变量,规则需要将信息传递到祖先结点上,然后将其将其向下传递给每个表达式,对于每个叶子结点,规则需要抽取相关的信息
这样做的后果是我们会构造非常大而且非常复杂的属性集合,而且动用copy在整个解析树上流动
对于execution-cost estimator的提升
因为实际寄存器的数量有限,我们需要对before和after set的数量做限定,限定为寄存器的数量,因此在实际计算过程中,我们需要对寄存器的占用进行考虑,我们考虑是否由寄存器空闲的情况,和当寄存器没有空闲的evict策略
Attribute-Grammar 算法的问题
许多实际应用attribute-grammar的应用都假定属性结果应该被维护,典型的以attributed parse tree的形式被维护
handling Nonlocal Information
attribute grammar 模式适合处理信息流动都是同一个方向的问题,如果问题中有非常复杂的信息流动方式,attribute-grammar很难去表达
attribte grammar只能应用出现在同一产生式的的语法标志对应的属性值,对应于语法树就是local information,紧邻的父子兄弟结点,如果想应用nonlocal,必须要采用copy技术,copy会极大地扩大attribute grammar的size,和复杂度
Storage management
实际过程中,计算会产生大量的属性,而copy的使用又会增加这个值,我们需要对属性进行内存管理
我们可以回收那些不会再被使用的属性值的内存,例如某些只作为中间计算转化的结点,但是,如果编译器要求保持属性并应用于接下里的检查,会导致我们无法回收内存
Instantiating the Parse Tree
attribute grammar的存在非常基于parse tree的存在,但是很少由编译器去构造parse tree,一些编译器会使用ast,我们可以将attribute grammar附加在ast上,但如果ast没有其他作用的话,构造和维护ast的负担远大于attribute gammar提供的便利
Locating the Answers
attribute evaluation生成的结果是一个attributed tree, 所有分析的结果分布在树上,为了得到特定的结果,我们需要对树进行遍历,而这使得代码十分慢并难以实现,我们也可以将一些重要的结果保存在易于寻找的结点上,这会用到copy问题又会出现copy的相应问题
Breakdown of the Functional Paradigm
我们可以建立全局可见的中心仓库去解决nonlocal问题,由于相关记录全局可见,某些规则不通过attribute rules去利用这些值,那么会影响构造出的attribute偏序图的偏序关系,无法满足rule的函数式特点,一个值的结果不止会由local的输入决定,也会由其他输入影响。