- 简介部分
Logging, failure and Recovery Methods
对于log: 作用: 记录transaction的进度。可以被用来恢复已commit但由于crash或failure而丢失的数据,也可以用来撤销未commit的transaction对系统的改变.
概念:log可以被理解为线性的增长的文件,每个log都会被给予一个LSN(log sequence number),LSN以增长的方式赋予
写入过程:log 会最先被写入volatile storage中,待到特定的时间点:例如commit的时候在某个lsn之前的log会被强制写入stable storage中,这个过程称为force.也可以在后端阶段性的写入
Log通常只记录一个页,但也有例外.
Log会以undo或者redo分类
记录信息方式: - physically: 例如会记录某个特定值更新前后更新后的映像
- operationally: 例如记录为record 5的field 3加5
对于 WAL protocal: - in-place updating: 更新的页会覆盖stable storage上原先的页
- 在记录某页更新的信息的log被写入stable storage之前相关的页不能被写入stable storage
transaction与log:
transaction的状态也会被记录到log中,transaction只有在其commit status和相关的log都被写入到stable storage之后才会被认为commit.
这可用来恢复一个已提交的transaction但是相关页没有被更新到stable storage中.
以上过程也可以理解为只有一个transaction的所有redo信息被记录到stable storage后才可以被认为已提交
transaction运行时的相关概念;
forward processing: system在正常状态,transaction正在更新系统,没有回滚,没有基于log的undo
partial rollback: 在执行的时候建立一个savepoint,然后transaction被要求回滚的时候回到上一个savepoint
total rollbalck: 整个transaction所有的更新都被undone,然后终止
nested rollback: 一个接一个的回滚
normal undo:一个系统在正常状态下某个transaction被要求回滚,一般发生在transaction request或者检测到deadlock或者不满足限制性条件的时候
Restart undo:顾名思义
所有被一个transaction写的所有log都由preLSN连接起来
在许多WAL系统中,回滚过程中所进行的所有更新都被compensation log records记录
Page-oriented redo描述了一个log record记录了哪个页在normal processing中被修改以及在redo过程中需要对该页进行处理, 该log正在被执行redo的过程称为page-oriented redo
page oriented redo 在执行过程中不需要访问索引和table的内部结构.
但是logical redo会需要访问数据库的内部结构和索引,甚至需要对索引进行修改,由此有可能会访问多个页.
page oriented redo可以允许系统提供recovery independence from object.
即对一个页的修改不需要访问其他页
logical系列操作能提供更高的并发性,page-oriented能提供更好的recovery.
Latches and Locks
latch类似于信号量,可以用来保证数据的物理一致性,而lock用来保证数据的逻辑一致性。
latch被持有的时间一般比较短,所以deadlock不考虑相关情况.
latch一般操作代价会比lock小很多.因为latch一般在virtual memory的固定位置存储,而且基于latch的name可寻址,一般transaction保有的latch数目很少,所以latch request block可以被永久的开辟给一个transaction,而且用transaction ID初始化.
lock需要被动态的开辟,格式化和收回,由于lock的数目比较多,一般transaction会保有一个hash table用于获得相关lock的信息.
lock的模式,前面博客里提到过
Lock的request 分为conditioal和unconditional.
conditional意味着如果lock不会被立即授予的话, 请求者不会wait,而unconditional则相反.
lock有着持续时长,instant lock意味这lock不会被实际授予,但是lock manager会推迟返回lock call直到lock可授予.
commit duration是指lock直到transaction终止的时候才会被释放.
manual lock指的是中间情况.aries系统整体概况
aries使用log记录对数据库的变化,使用wal机制,同时在rollback过程中使用log进行记录,(compensation log records CLRs).
即在undo过程中诞生CLRs,
在aries中,CLRs是redo-only log records, 在forward procesiing中将有效的clrs嵌入到log records中,能有效的保证TT在回滚过程中log数目的有限性.
具体过程如图:
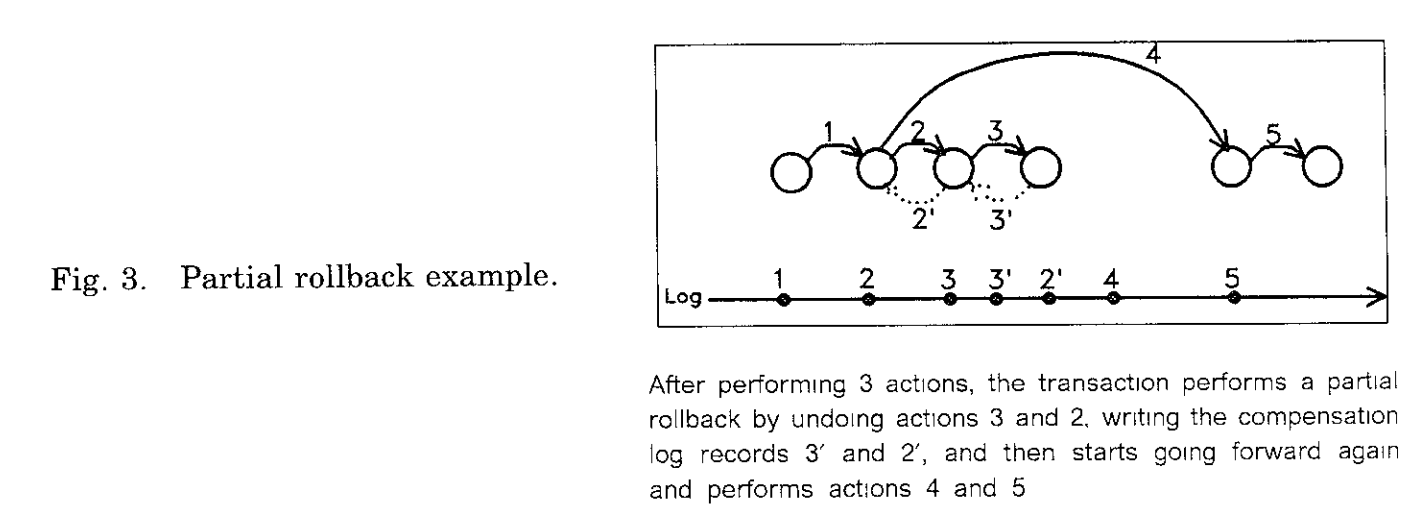 如果clrs是undo log,会在未来的多次failure中产生一大堆对于以前clrs log的clrs log,影响性能.
如果clrs是undo log,会在未来的多次failure中产生一大堆对于以前clrs log的clrs log,影响性能.
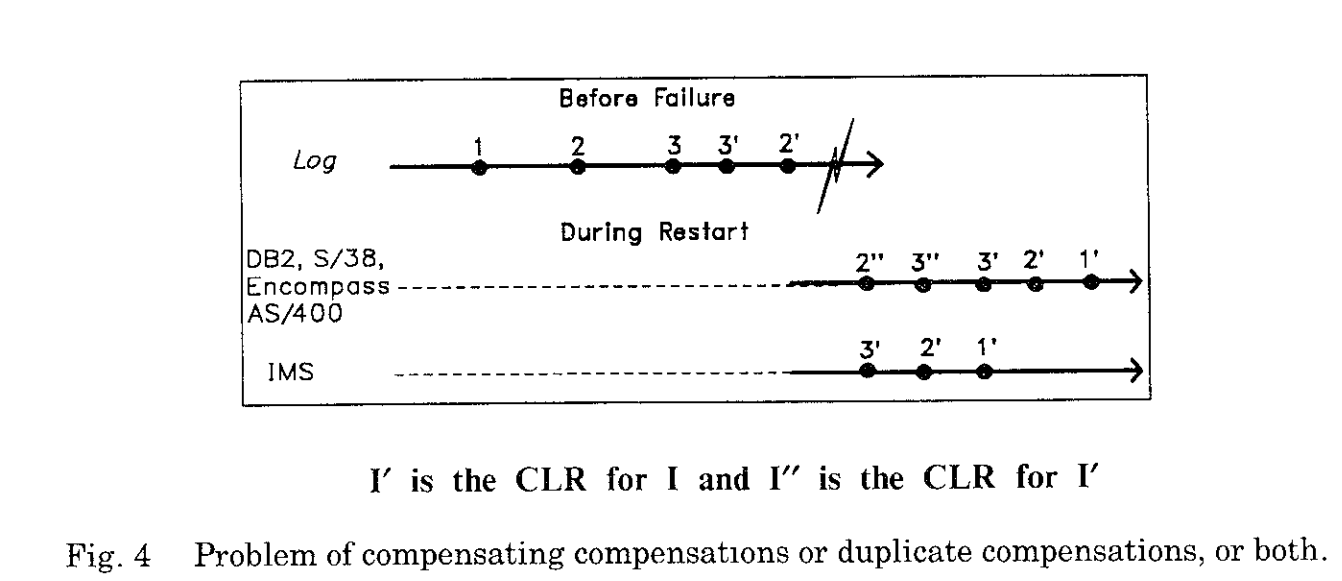 那么在aries中该问题是如何被解决的:
那么在aries中该问题是如何被解决的:
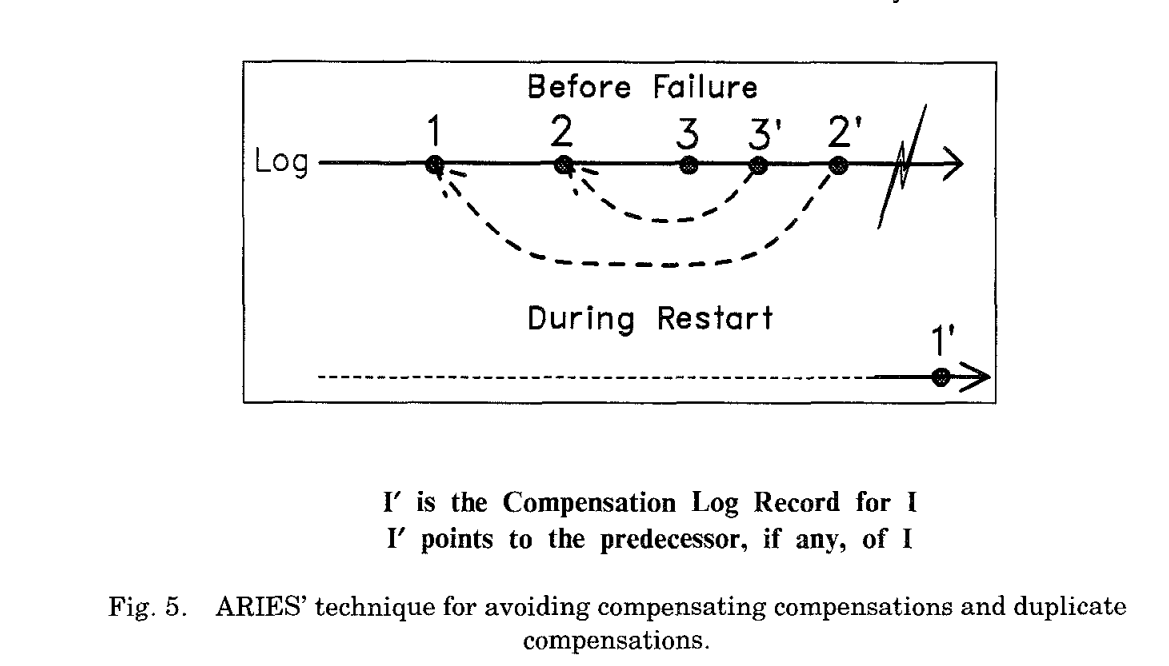
在clr中有一个UndoNXTLSN,指向恰好撤销的Log的先序节点,该节点决定了一个transaction中还有多少未被撤销.
因此在rollbakck过程中,clr的 undoNXTLSN追踪这rollback的进程,它告诉系统从哪里开始继续回滚,如果一个回滚过程失败或者有nested rollback,系统可以根据这个undoNXTLSN来绕过那些已经undone的log.
具体情况如图所示;
 由于clrs能够很好的记录undo过程中采取的行动,我们可以不必将undo限定为对某一特定页的相关行为的反转,而clrs的redo则是对特定页的行为的描述,提高了其高效性.
由于clrs能够很好的记录undo过程中采取的行动,我们可以不必将undo限定为对某一特定页的相关行为的反转,而clrs的redo则是对特定页的行为的描述,提高了其高效性.
aries将相关log的lsn放置入相关page的lsn中.
aries阶段性的建立checkpoint log. checkpoint log用来判别哪些transaction还在活跃,其相关的最新的log的lsn,还有在bufferPool中被修改的数据.
restart recovery过程:
第一步:analysis pass: 在checkpoint 和log结束之前的正在进行的transaction和dirty page信息被更新.
analysis pass利用dirty page的信息确定在接下来的redo pass中进行log scan的起始点.redoLSN
同时它还确定在undo pass中回滚的transaction的列表.
第二步: redo pass:
对于每一个其更新已经被log到stable storage上,但是其对于数据库相关页的影响还没有被储存在nonvolitile storage上的操作,系统重复其历史,这个过程要对所有transaction redo.
包括那些既没有被提交也没有在2-phase commit中到达in-doubt 状态的transaction.
一个log record 的更新要被 redo取决于其所影响的page的lsn小于log record对应的lsn.
下一步是undo pass:
在对log们进行单向的逆序的扫描过程中,要对所有的loser transction进行undo.
将每个没有完全撤销的的loser transaction,不断的处理具有最大lsn的log,直到transaction被处理完毕。
undo是一定会被操作的,不会通过判断page的lsn和log的lsn进行判断,如果遇到redo-undo log, undo-only log,其对应的更新一定会被撤销,如果遇到clr,则会跳过,找undoNxtLSN.
对于那些已经部分回滚的transaction,aries仅仅会回滚那些还没有回滚的操作。这是由于clr可以指向上一个没有被undo的log.
而只要涉及到基于页的undo和 logical log只产生对应的clr,那么clr的数目将会完全等同于undoable log的数目.
Data structures
列举: LSN, Type, transID,PrevsLSN, PageID,UndoNxtLSN, Data.
type: compensation, update, commit protocol-related record, nontransaction-related record.
data 记录了transaction正常处理过程中的更新信息,可以以逻辑的形式记录.
Page Structure
page_LSN是每个page都有的field,它记录了对该page最近更新的Log的lsn.
aries 只对buffer manager要求wal 机制,不要求其他机制.
更新会当即应用到相关对象相关页的缓存版本中,不会使用延迟更新。但是系统足够灵活,他也可以实现延迟更新.
transaction table用来在重启恢复中追踪活跃的transaction的状态.
该表这analysis pass中从最近的checkpoint records 中初始化并且在后续过程中修改,如果一个checkpoint在重启初始化过程中被采用,那么表的内容将会被checkpoint records包括.
同样的表也会在正常处理中被使用.
表的内容:
TransID
State: transaction的提交状态: prepared或者 unprepared.
LastLSN: 由transaction写的最新的lsn.
UndoNxtLSN.
Dirty_Pages Table
dirty_pages table用来表示在正常处理中dirty buffer pages.
这个表的实现实际依赖着hashing或者通过 deferred-writes queue mechanism.
table中的每个entry包含pageID和RecLSN,在正常处理中,一个正常非脏页开始被修改时,buffer manager 在buffer pool dirty pages中做记录,同时还有RecLSN,记录的是当前log结束后的下一个lsn,即下一个被写入log的lsn.
RecLSN表明从哪个log结点开始相关log记录的内容又可能没有被刷到non-volatile memory中.如果记录的log的更新已经被刷到non-volatile memory中后,则更新相关的lsn.
5 Normal processing
5.1 updates
transaction将会进行前向处理,部分回滚或者全部回滚.
更新过程:
如果锁的粒度是record,当更新在该page的record时候,record上锁, 相关缓存中的page被固定,latched in the X mode,然后进行更新,同时相关的log被加入到log序列中,lsn被放入page的相关page_LSN中,并放入transaction table中,
page latch由logger持有。这样保证记录对该页更新的log的顺序与对该页进行更新操作的顺序相等。
page latch必须读和更新的时候被持有来保证物理一致性。
这是十分有必要的因为在对page中的record进行插入和更新时有可能由于要进行garbage collection而要进行对record的移动,如果有其他transaction进入的话会搞不清状况。
在相关index操作进行时data page latch不被持有,最多会有俩个page latch会被同时持有,这意味着对于俩个transaction 有可能对 data page是一种操作顺序,对index page是另一种操作顺序,而这再以lock为主导的数据库中是不可能的.
对datavase中出现的failure的讨论:
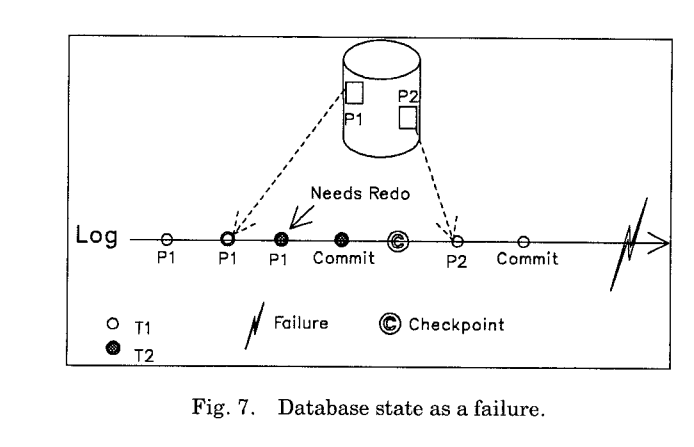 在俩个transaction commit之后发生了failure,虚线代表磁盘上page最新状态,可以看到,在restart过程中,我们需要对p1进行redo,而p2则不需要,这种情况指出我们需要利用lsn,将在磁盘中page的状态和和在log中确切的位置关联起来,同时要在checking log中记录从哪里开始redo.
在俩个transaction commit之后发生了failure,虚线代表磁盘上page最新状态,可以看到,在restart过程中,我们需要对p1进行redo,而p2则不需要,这种情况指出我们需要利用lsn,将在磁盘中page的状态和和在log中确切的位置关联起来,同时要在checking log中记录从哪里开始redo.
5.2 total or partial rollback
这里引入一个概念: savepoint,savepoint 可以再txn进行的任何时间点被建立,在某一时间点的任意数量的savepoint都有可能是未完成的,意思结合下文我认为的理解是savepoint在没有回滚前都是不断建立的过程,直到回滚到特定savepoint则该savepoint才是已经建立的。接收到命令之后,txn撤销在特定savepoint之后的更新,经过一次部分回滚后,抵达的savepoint不再是未完成状态,而是以前的状态,文中还提到如果抵达先前的某savepoint(1)之前的savepoint时,1也不再是未完成的状态,我认为1直接消失了,如果一个savepoint已经建立,则其log中最近的log的lsn(saveLSN),会被记录在虚拟内存中,如果roll back到特定savepoint时,系统提供对应的saveLSN进行操作。
伪代码如下:
 这个算法中注意的点: 回滚过程中不需要lock,但对特定页操作时需要latch,避免死锁,
这个算法中注意的点: 回滚过程中不需要lock,但对特定页操作时需要latch,避免死锁,
clr解决了很多问题.
特殊情况:当一个transaction在建立了一个savepoint之后,并在savepoint之后获得了一个锁,而该savepoint是此次roll back的目标,那么该锁在rollback之后被释放。
5.3 transaction Termination
采用two-phase commit的方法来处理transaction termination, 引入了prepare record, 他是2pc协议的一部分,会被同步的写入log中,其中包含了锁的信息。对锁进行log代表当txn进入in-doubt状态时,突然系统崩溃,恢复时这些锁要重新获取,以保护未提交的更新。为了处理那些会删除文件内容的操作,为了避免记录要删除文件的内容,我们将相关操作延迟记录入prepare log中,待到相关txn提交后,再执行。
in- doubt 的 txn提交过程: 写一个end log 并且释放所有锁。一旦end log写完,所有pending action都将被执行,涉及到修改文件或者把文件返回到系统时,相关log一定是redo-only log.
一个in-doubt的transaction进入回滚时通过写一个回滚记录,回滚到开始,忽略pending action,释放所有锁,最后写一个end record.
5.4 checkpoints
checkpoint 阶段性的构造来减轻恢复的工作量,一个fuzzy checkpoint的开始通过写一个begin_chkpt record来开始,而通过构造一个end_chkpt record结束而结束,当end_chkpt构造结束后,它被写入到log中,当该record 被写入到stable storage中后,begin_chkpt的lsn也被写入到stable storage中叫master record的地方中,有一种可能是end没有被写入而begin被写入,此时出现内存错误,这种情况是incomplete record.
end chkpt中记录的东西: transaction table, BP dirtypage table,还有文件对应映射的东西.
在二者之间system 也会写入一些其他的record,如果一个transaction长期处于in-doubt的状态,那么end chkpt 也需要将锁的信息保存。
通过读取脏页表收集相关信息有可能用到latch,所以我们一次操作要尽可能的多收集信息。
如果一些已经被检验的entry在chkpt之中被就更改,recovery 算法依旧保持正确,因为恢复过程中不仅恢复checkpoint,同时也恢复在chkpt之间的log.
在checkpoint构建过程中相关脏页不会被强制写入non-voletile storage中,会有一个后台程序持续的将dirty page批量的写入到磁盘中,对于hotspot,db也可保持其持续性,思路采用copy方法,io处理一个copy,对该页更新则在另一个copy上.