AD HOC SYNTAX-DIRECTED TRANSLATION
上下文敏感所做的分析行为可以根据语法的结构进行组织。
ad hoc syntax-directed translation, 可以将这类分析融合在parsing context-free grammar
行为模式:
提供一小段代码,直接和语法中的产生式关联,每次parser判断出语法中相关部分,相应的代码就被调用去执行其任务
无论是top-down还是bottom-up,都可以完成类似任务
举例: 如图所示
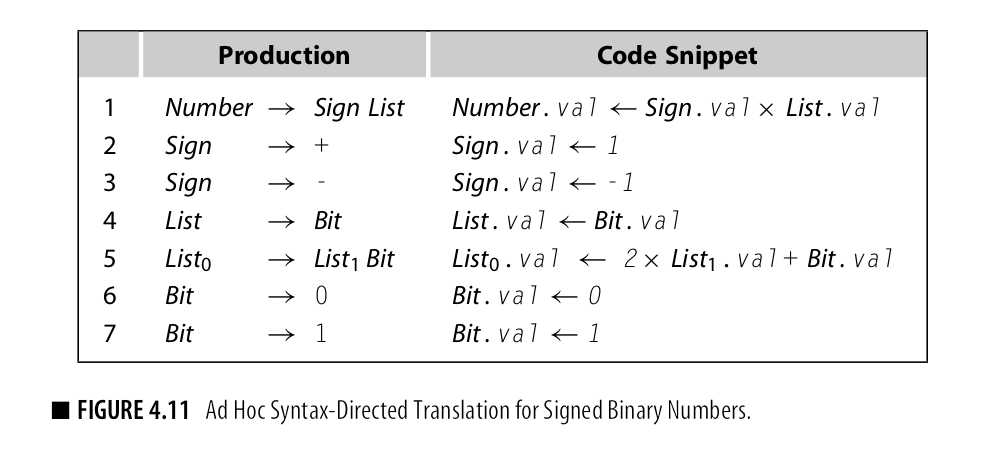 相比之下:他和attribute grammar好像没有区别,但是他做了俩个重要的改进:
相比之下:他和attribute grammar好像没有区别,但是他做了俩个重要的改进:
- value只朝一个方向流动,从叶子到顶部
- 对于每一个grammar symbol,他只允许单一一个值
这两个改进对于使得计算方法对于bottom-up parser工作的十分好,具体改正如下:

Communicating between Actions
需要开辟空间存储不同行为产生的值.
attribute grammar 将值和parse tree的结点相关联,将二者的存储放在一起,而ad-hoc并不生成并不构造parse tree,转而代替的是:将值的存储和对parse状态的追踪放在一起,使用parse时的栈
在LR(1)parse过程中,对于每一个grammar symbol,栈存储符号和相应状态俩个值,没一个符号对应栈中一个pair(symbol, state),我们可以将其替换为(value, symbol, state),这个存储方式易于得到相对于栈顶值的位置
values被限制在一定大小,意味着一定情况我们可以采用指针,
为了节省空间我们可以省略实际的grammar symbol,而将相关的信息编码在state中,但是另一方面grammar symbol可以用来实现debug,这涉及到取舍Naming Values
compiler writer需要一个为其命名的符号来简化基于栈的值.
yacc 采用的符号来解决这个问题,$0表示当前产生式的结果,$1表示production右侧的第一个符号
同时,注意其与栈中位置巧妙的对应$1表示 离栈顶3 $\beta $位置,而 $i 则表示 3 ($\beta$ -i + 1)位置
Actions at other Points in the Parse
有些行为会在产生式的中间或者在移动终结符的过程中发动,为了完成以上做法,我们可以做如下改进:在action被需要的结点处执行reduction操作
- 为了在production中间完成reduce操作,我们可以将production拆分为俩部分,由point开始拆分
- 为了在shift下开展行动,我们可以在scanner和增加production完成action
Examples
attribute grammar 的缺点是要根据树来复制传递信息
为了解决这个问题,hoc 方法引入了central repository来存储变量的信息
由于parser决定了计算的顺序,我们无需担心打破破坏属性之间的依赖关系
大部分编译器建立了symbol table, symbol table将name和许多种类的信息映射起来,例如类型,运行表示的大小,用来生成运行地址的信息
运行时间计算基于ad hoc
建立相关symbol table,一个identifier和bool,bool为true时该load已经被计算,计算过程如下:
![]() 我们在action中可以添加任意代码,因此我们可以积累计算cost而非为树提供结点
我们在action中可以添加任意代码,因此我们可以积累计算cost而非为树提供结点
这种方式采用的行为要比attribute grammar更少,却能提供非常好的精度
整个计算过程更简单,更清晰,我们无需维护和传递before和after的集合,只需追踪action中的相应的load的计算
计算过程完美符合parser的reduce过程,注意维护symbol table
在ad hoc 框架下考虑类型推断
attribute grammar 在这个问题上表现的非常好:
- 表达式类型是基于解析树递归定义的,信息流动自底向上,满足s-attributed
- 表达式类型是基于源语言的语义,需要隐性的解析树的存在,满足attribute-grammar框架
最终模式如下:
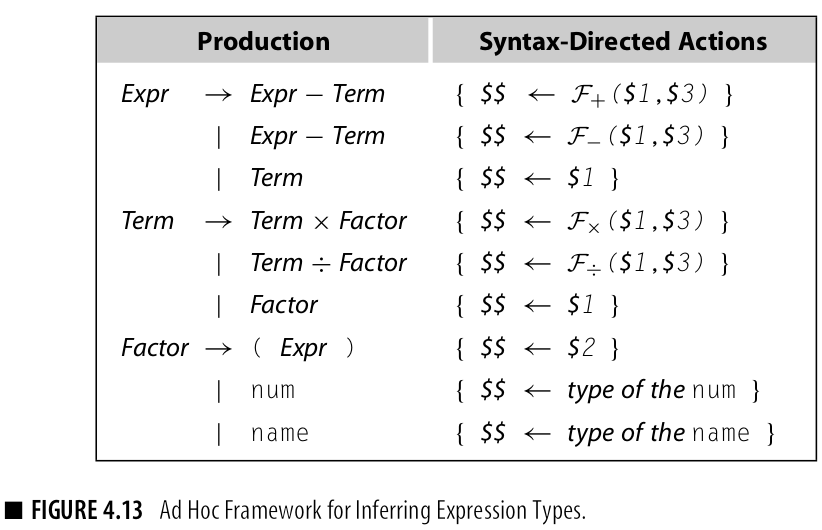
ad-hoc没有明显的优势
Building an Abstract Syntax Tree
compiler前端需要为程序建立中间表达式, AST是一种非常常用的表达方式
我们可以通过ad hoc建立AST
我们采用一个程序 $MakeNode_{i]$ ,第一个参数表示新节点所表示的语法符号的常量,后续i个参数表示其子树

构造过程中我们需要满足俩个原则;
- 对于operand,它开创有孩子的结点:
- 对于无用的production例如 Term->Factor,我们可以重用结果