intruduction
我们需要服务器端多server协同工作的的程序,zookeeper提供了一个通过暴露相应API的方式来使应用者自己实现相关primitive的方式.
Zookeeper不使用block机制,而是使用用文件系统架构组织的wait-free 数据对象.
Zookeeper要保证操作的执行顺序,通过FIFO client ordering 和linearizable writes 来实现.
我们使用一种 pipelined archtecture 来允许我们在保有大量的请求的时候依然保持低延迟.这样可以允许不同的client异步的提交操作.
对于pipeline的进一步解释:
pipeline是相对于client API的操作而言的,client对于这些api的操作是异步的,它调用这些操作,将其发送给zookeeper,然后返回,zookeeper会对client进行回调,告诉操作已完成,并返回结果。这样的话client在安排相关操作的时候,无需等待相关操作完成便可以安排下一个操作.这样做有可能会导致相关操作的无序性,所以保证fifo很重要.
为保证更新操作的线性化,我们实现了leader-based atomic broadcast protocol 称为zab。对于读操作,我们用server本地化来执行,不经过zab.
cache: Zookeeper使用watch机制来允许client去缓存数据而不需要直接操作client的cache. watch操作思路: 设置为true时,client将会收到信息的变动的消息而不需要主动请求,该操作不会告知具体变化了什么,sesstion event 也会通过watch call back 返回给client.
The Zookeeper Service
data model
以下是data model
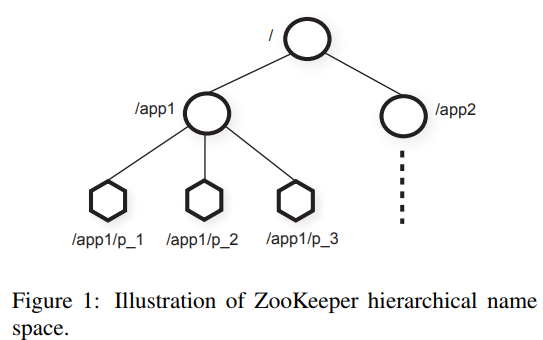 类似于文件系统,每个子树代表一个app.
类似于文件系统,每个子树代表一个app.
znode不是通用存储系统,但可以存储meta-data.
Session: client连接zookeeper,开启session,session有timeout, 在session内,client可以观察到代表operation操作的状态的变化,通过session可以允许client从一个server转化到server.
Zookeeper的api:
zookeeper的api有异步的和同步的,同步的每次执行一个operation且没有并发的任务,它调用zookeeper call并且block.异步的每次有多个待执行的operation并且有并发的任务,由zookeeper来保证每个operation调用的有效性。
zookeeper不需要handle来访问znode.
每个update会附加一个version number用来实现conditional update. version number如果和对应znode math,则可更新,否则返回err,-1不进行version number checking.
Zookeeper guarantees
俩个保证:
Linearizable writes和FIFO client order:
linearizable write : 本文的linearizable是asynchronous linearizability.一个client会有许多正在执行的operation,可以理解为client会有许多thread, 我们对于许多的operation, 可以选择非特定的执行顺序,也可以选择FIFO order.我们选择后者,支持A-linearizability也可以支持linearizability. 用一个问题来看这俩个guanrantee是如何作用的:
多个process, 选举leader, 修改配置参数,完成后通知其他process.
满足俩个重要的条件:
- 当leader改变configuration的时候,其他process不能使用正在改变的configuration
- 如果leader在configuration未完全更新完毕时死机,其他process不能够使用部分的configuration.
leader可以设计znode,其他process只有在该znode存在的时候才能使用configuration.leader在更新configuration过程中删除znode,更新完毕后添加znode,这种方式可以很好的解决以上俩个问题.
遗留问题和解决方案:
某一个process 看到ready znode在leader即将更改相关configuration时候,然后process读取configuraton和leader更改configuration同步,会发生什么,
通过notification的顺序保证来解决这个问题;
client通过watch机制观察znode的变化,如果一个znode变化的时候,相关client收到相关的notification在更改完成之前.
另一个问题:
假设有俩个client A和B, 他们既在zookeeper中共享configuration,也有一个communicate channal,如果A改变了共享的configuration,并且通过channel通知了B,但是由于B的server的replica稍微慢于A的,此时read不会读到最近更新的信息
引入sync request, 后面跟随read request, sync可以使server去应用所有等待的write.
Example of primitives
- Configuration Management configuration存在znode中,process通过访问全路径来访问znode,一些process获取znode中的configuration, 并为该process提供watch机制,具体操作思路如上所述.
- Rendezvous 出现问题:
在分布式系统中,我们无法提前知道系统的配置信息,举例: client有可能开启几个process,一个master和几个worker,但是由于process开启工作交给调度器,所以我们无法提前知道master的地址和端口,worker也就无法联系,但是client可以在zookeeper中设置rendezvous node,将其full path name传递给master和worker,当master开始时,将相关信息填入到znode中,worker读取znode并设置watch机制,问题可以得到解决. - Group membership 用 ephemeral znode来表示group membership,首先设置znode Zg,然后在Zg的路径之下每开启一个新进程就放置一个ephemeral,如果进程有名字的话将进程名字给予znode,否则在创建znode的时候利用sequetial flag命名.
- Simple lock 如何用znode实现最简单的lock: 让process开创一个设定好的有ephemeral lock的znode,如果开创成功则获得锁,如果开创失败就对已开创好的znode设置watch机制,等到相关znode的process死亡之后再去获得锁.
Simple lock without herd effect:
设计znode l去实现相关锁,并将请求锁的client排序,具体过程如下:
 每个client 在l之下开辟新的znode,如果开辟的znode在相关的l之下的znode集合之下拥有最小的序列号,则拥有lock,否则找到其前一节点,设置watch机制,如果前一结点消失则在继续上述过程.
每个client 在l之下开辟新的znode,如果开辟的znode在相关的l之下的znode集合之下拥有最小的序列号,则拥有lock,否则找到其前一节点,设置watch机制,如果前一结点消失则在继续上述过程.
read lock 和write lock的机制,设置俩种lock结点来处理问题: read和write.

Zookeeper Implementation
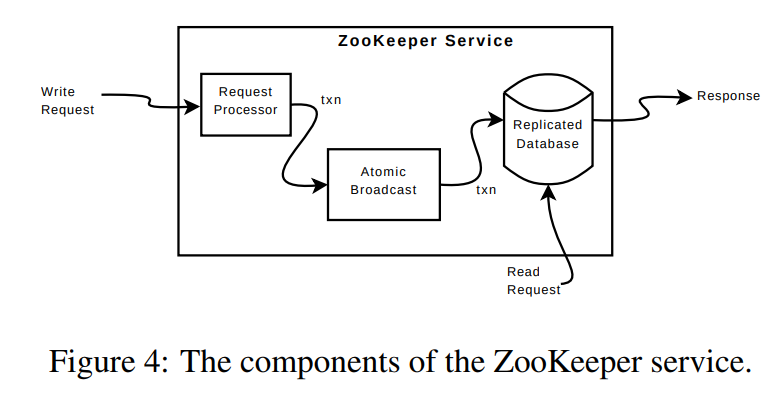 replicated database 是一个in memory 的database.如何为其增加recoverability呢:
replicated database 是一个in memory 的database.如何为其增加recoverability呢:
force write, replay log(write ahead log), snapshot.
处理write的agreement protocol 由leader和follower组成.
4.1 request Processor
要保证local replicas不发散,但在某一个时刻一些服务器有可能会比其他服务器应用更多transaction.transaction是幂等的.
当一个request processor接收到write request时候,先计算当write被应用时系统未来的状态并将其封装到transaction中,计算未来状态是必须的因为有可能有未完成的transaction还没有被应用到数据库中。
举例:
conditional setData其version number等于相关znode未来时刻的version nuber,则发送setDataTxn会包括新的数据,新的version number以及新的更新时间戳.
如果mismatch,则构成一个新的errorTxn.
4.2 Atomic Broadcast
所有有关于更新zookeeper的请求会被发到leader那里,leader通过zab执行请求并broadcast.
为了提高更高的吞吐量,zookeeper尝试使request process pipeline保持满的状态,由于系统state的变化依赖于以前系统的变化,zab提供了更强的顺序保证: zab保证leader所broadcast的信息一定按照其发送的顺序执行,而在leader广播自己变化的时候一定要将先前leader所广播的未执行的变化执行.
一些好的实现选择:
使用tcp保证信息的有序性,使用zab所选取的leader作为zookeeper所选取的leader,使用write-ahead log.
4.3 Replicated database
采用snapshot和snapshot之后的log来对系统crash之后进行恢复.
采用的是fuzzy snapshots,即在生成snapshot的时候不会对zookeeper的状态进行锁定.
采用的是对树进行深度优先遍历,并将相关数据和元数据存入到磁盘中,由于snapshot的生成和相关变化被更新到znode上是同步的,所以有可能生成的snapshot不会等价于任一时刻系统的状态,不过不会影响后续恢复的进行.
4.4 client-server interactions
当server处理write request的时候,它会分发和清空与这次更新相关的设定了watch机制的notification,server的write按顺序执行,并在执行过程中不并发的处理其他write和read.
server仅在本地处理notification,仅与client连接的server会为client跟踪或触发notification.
read request 处理仅在本地进行,每个read request都被给予了一个zxid,等同于server所看到的最后一个transaction.zxid定义了与write request相关的read request 的偏序.将read 在本地化处理提供了很高的性能.
fast read有可能会读到陈旧的数据,我们提供了sync,它可以异步的执行,sync会被放置在所有待执行的write的后面.
对于sync,我们不需要像使用leader-based algorithm那样对他进行原子化的广播,而是将sync放入到leader和请求sync的server的request queue的末尾.这样需要follower确认leader还是leader,当pending transaction不为空的时候,说明leader还是leader,如果pending queue为空后,则leader发送null request保持leader的身份,在本文中我们采用timeout来保证leader.
如何保证durability:
zookeeper server和client在request 和response的过程中交换zxid,server要保持至少和client一样最新的状态。
如何检测session failure:
采用request和heartbeat 和timeout保证交流,如果出现timeout, client重新选择server并建立相关session.