introduction
为了满足逐渐增加的计算和存储需求,我们利用集群上分片(sharding)技术来处理数据
现在技术通常利用key-based hash和range partitoning来时实现sharding和load balancing
我们还需要考虑fault-tolerance和hign availability,一种方式是使用同步的master-slave replication
master-slave replication的局限和paxos的适用场景
局限性: 当slave突然down的时候master继续接收log,但是slave无法接收(因为已down),这样当master down的时候slave恢复,由于slave不保有database的最新状态,无法进行读写操作,如果master永久down的时候,该部分log也就永久失效
唯一的解决方式是当俩个节点有一个down的时候blocking write,但是它又会损失availability
另一种方式: 采取3-way replication,可以有效的扛过disk failure,减轻控制任务。但是需要仔细的维护一致性,应用paxos
Strong vs. Eventual Consistency
CAP理论: consistency, availability, 和partition tolerance.三者最多能满足其中之二.
partiton tolerance 是指网络的切分, 例如跨数据中心的能力,不满足这个是指只有一个数据中心
Spinnaker
Spinnaker 支持的特性:
- key-based range partitioning
- 3-way repliation
- transactional get-put AP以及选择一致性能力(strong consistency 和 timeline consistency)
timeline consistency是指有可能返回陈旧的数据但是能够有一个较好的性能
Spinnaker使用 paxos-based protocol来管理replication同时集成了commit log和 recovery processing.
Spinnaker是一个 CA系统
,假设只有一个数据中心
Data model and API
spinnaker支持的API类似于普通数据库的api, get, put, delete,不过为了optimistic concurrency control,也加入基于version number的get和put
Architecture
基于范围进行replication的分布
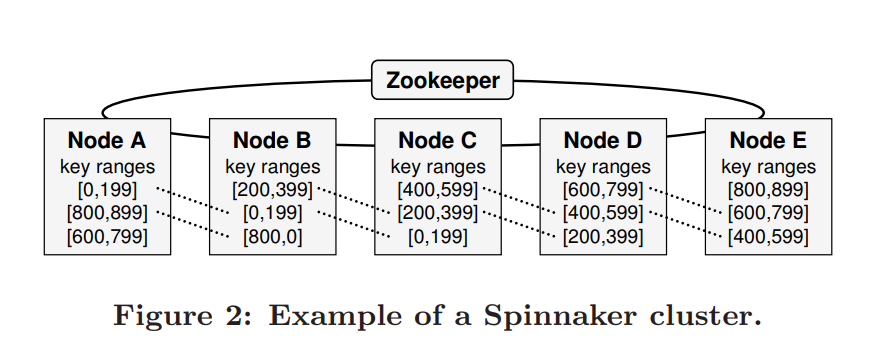 cohort: 涉及到同一个replication的一组节点.
cohort: 涉及到同一个replication的一组节点.
例如A,B,C是[[0, 199]的cohortNode Architecture
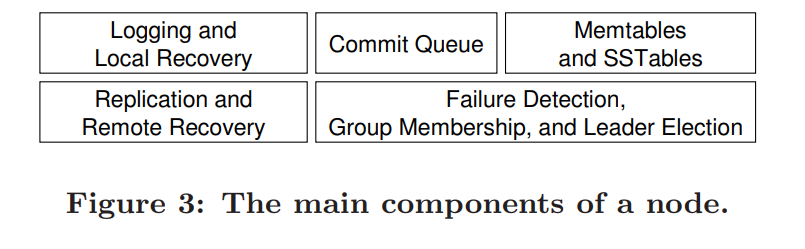 其中commit queue用来追踪待commit的write的队列
其中commit queue用来追踪待commit的write的队列
Memtables and SSTables用来apply write并刷到磁盘上Zookeeper
用来简化Spinnaker的设计,实现distributed locks, barriers 和group membership等等
The Replication Protocol
具体流程如下:
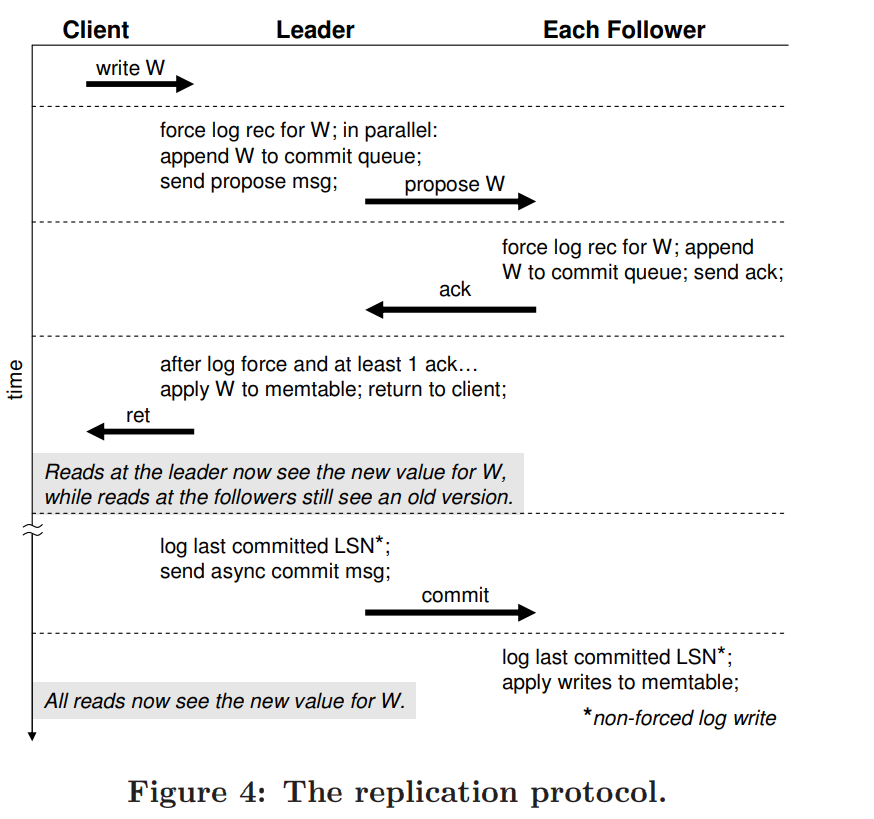 commit period: 在一段时间里,leader已经apply write但是follower还没有apply,这段时间follower上面还是stale data,所以需要commit.
commit period: 在一段时间里,leader已经apply write但是follower还没有apply,这段时间follower上面还是stale data,所以需要commit.Recovery
Follower Recovery
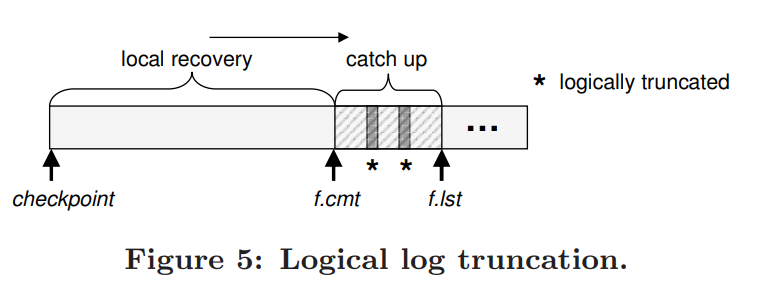 f.cmt 指在follower中最后被提交的节点,f.lst指在follower中最后存入磁盘的log
f.cmt 指在follower中最后被提交的节点,f.lst指在follower中最后存入磁盘的log
logically truncated: 在follower中由于leader转换有可能会存在follower中有的log在leader中没有,这时候我们需要消除该log,但是由于一个节点是多个cohort的成员,有可能log对这个range没作用,对另一个range有作用,我们采用logically truncated,将要消除的节点组成链表存在磁盘中进行对比Leader Takeover如何接管
旧的leader坏掉,新的leader被选举出来,让follower和新的leader同步,思路类似于raft:

Leader election
利用zookeeper实现leader election,算法如下;
