Abstract
MapReduce是一个编程模型,用来处理和生成大型数据。其中map处理键值对,用来生成一系列中间pair,reduce用来将同一键的值集合起来。
以这样模型生成的代码并行化且隐藏了切割数据,调度机器的细节。
Introduction
问题描述:要处理大量原始数据,并生成数据,由于输入较大,将任务分布到计算机的集群上,这样就诞生了复杂度:并行计算,数据分布,以及处理失败,
因此需要设计一种模型:
- 能够表达我们进行的简单计算
- 隐藏paralization, data distributed, fault-tolerant, load-balancing
灵感来源: lisp的函数式编程
编程模型
输入:键值对,输出:键值对
map, 由user指定,由输入键值对生成一系列中间键值对。
MapReduce library将对应于同一键的所有值分组集合起来,传递给reduce。
reduce, 用来对某一个键的值集合进行处理,来生成更小的集合,通常输出0或个output,对于值集合,我们常采用iterator举例
 中间键值对处理由mapreduce library组成, 值域关系:
中间键值对处理由mapreduce library组成, 值域关系:
map (k1, v1) —>list(k2, v2)
reduce (k2, list(v2)) ——>list(v2)
其中input 和 output不属于同一个值域,但output和intermdediate属于同一个值域
###实现谷歌实现对应的硬件环境
- 双核 x86,linux, 2-4G内存
- 网络设施。mb/s或gb/s
- 大量机器集群,机器失败可能性高
- 内存分布式,机器共享
- user提交工作,schedule system分配任务
excution
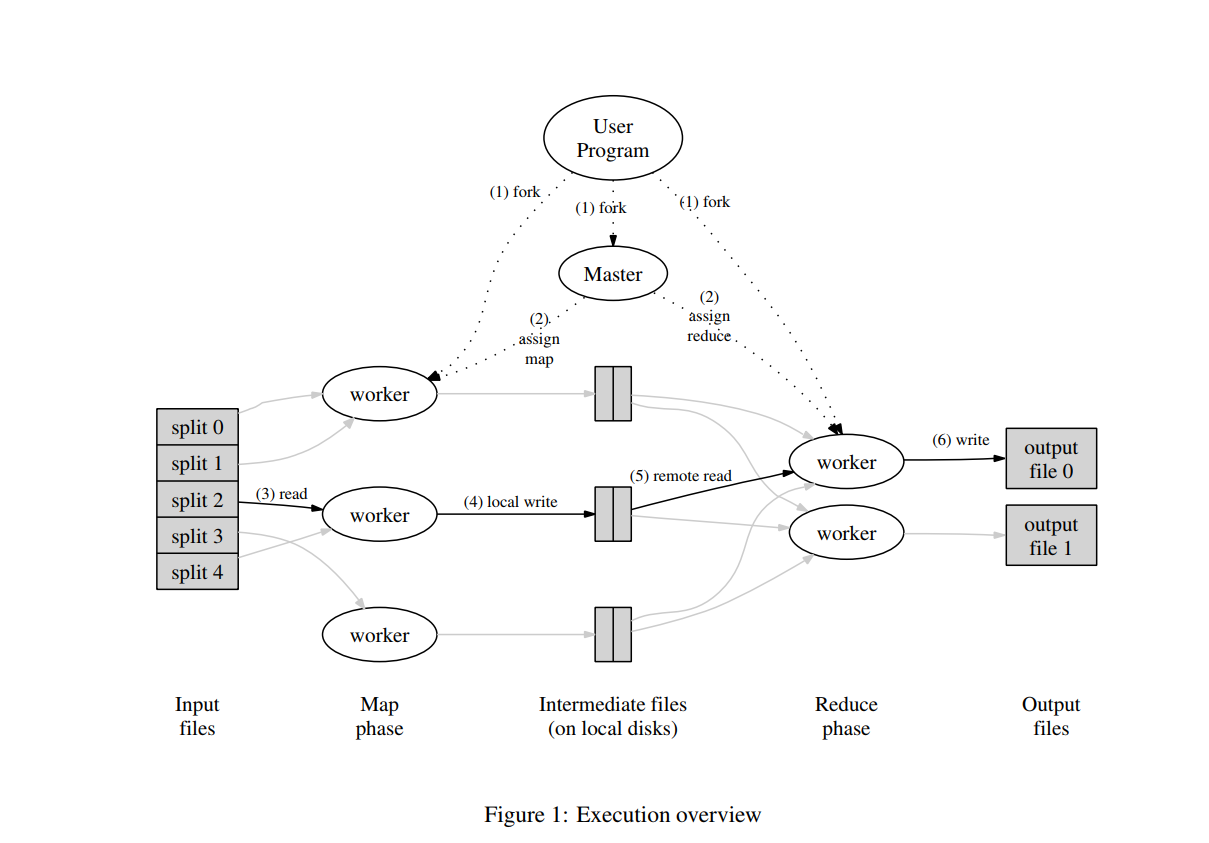 具体执行流程如下:
具体执行流程如下: - user program将input分成 M块,每块16MB, 64MB,然后启动集群上的复制代码
- 其中一个机器用来执行master,给worker分配任务,将M个map, R个reduce分配给空闲的机器。
- 执行map的机器读取Input,解析出键值对,由map处理,生成intermediate,缓存在memory中。
- 缓存的键值对定期的被写入磁盘中,且由partition分为R块,位置告诉maste以便后续任务分配
- reduce的机器通过rpc读取磁盘,对intermediate key进行排序,必要时采用外部排序
- reduce 机器iterate 排序后数据,对于key和对应的值得集合,交给reduce 函数实现,其输出被接在对应R块的输出文件中。
- 任务完成后,返回到用户程序
输出为 R个output文件,可以对其继续用mapreduce或者用distributed 输出实现
master数据结构
对于map和reduce任务,维护其状态(idle, in-process, completed),和worked-machine的身份
同时是磁盘R region由map 到reduce的导管,它存储每个完成map任务的输出的位置和大小,并渐进的传递给reduce.
####Fault Tolerance 数据大量性和机器的集群性导致的问题worker failure
master 定期ping一下worker,如果ping不同,则认为worker failure,将该机器定义为idle,重新进行schedule。
完成的map任务需要被重新执行,因为其磁盘由于failure的缘故无法访问,而reduce则不用,因为其输出文件全局可见。
map任务由A转向B的话,所有执行reduce的worker会被通知该信息。任何还没有从A中读数据的reduce会从B开始读
MapReduce对于大规模machine failure是有弹性的,当出现大规模unreachable时,cluster会重新执行相关任务,并继续推进。master failure
阶段性记录checkpoint,失败换台机器继续从上一个checkpoint执行,master失败的可能性比较稀少,可以retry
Semantics in the presence of failure
当用户定义的map和reduce是对于输入的确定性函数时,分布式计算的结果和线性执行结果一致。
这一性质的实现是通过任务输出的原子性提交完成。
每个reduce生产一个输出,每个map生产R个文件输出
当map完成时,我们向master提交信息,信息中包含着map文件输出的名字,如果已经接受过同样的信息,忽略该信息,否则记录相关信息
当reduce完成时,他会对其暂时的输出文件进行重命名操作,当有多个同样的reduce任务完成时,我们可以依赖文件系统提供的atomic rename操作,使最终文件系统中只包含一个输出
####局部性 网络资源很稀缺,我们利用gfs存储数据,分配任务时尽量将任务分配到输入在local disk上或者靠近local disk的地方
####Task Granularity M和R通常要大于worker machine。
一个机器执行许多不同的任务可以提高动态的负载均衡,且一个机器故障时迅速恢复:将上面任务分发给周围机器
那么M和R如何选取: 任务分配的复杂度为O(M+R), 维护状态的复杂度为O(M×R),R由用户限制,M一般保持在是输入16MB到64MB之间。Bachup Tasks
遇到问题:
straggler: 一个机器花非常态的长时间来完成完成最后几个任务之一
原因: - 有坏磁盘的机器因为correctable problem导致读性能的下降。
- 多个任务的执行导致资源抢占
- cache被禁止
解决方式:
在MapReduce任务接近完成时,对于in-progress task进行备份执行,那个先完成算哪个,这样提高了资源的利用率。
Refinement
Partitioning Function
用户定义R个reduce,那么对于intermediate key如何切分到相关领域呢,hash,针对特定数据可以采用不同的切分方法。
Ordered Guarantees
对intermediate key处理时进行升序处理,使每个切分的输出文件sorted
Combiner Function
由于map会产生特别大的重复的key,所以我们可以在其向reduce发送时先进性一次combine来进行处理,combine和reduce区别在于输出不同,combine输出intermediate key, reduce输出 final output file.
input type
MapReduce支持几种input type.输入类型可以有效的对输入数据进行切分以满足mao任务的要求。
我们可以通过实现reader interface完成新类型的支持,且输入不局限于file
对output也同理
side effects
Mapreduce可以产出辅助文件,我们通过应用层保证其幂等性和原子性
对于单一任务产出的多个文件我们不保证原子化的俩阶段提交,因此跨文件的一致性需求应该是确定性的。
Skipping bad records
我们的mapreduce任务面对特定的record一定会crash,而在某些情况下我们可以跳过crash。
MapReduce library可以检测到相应的record并跳过他以继续执行。
具体实现思路;
worker process 安装一个signal handler来捕获segmentation violations and bus error,调用map和reduce之前,将参数的sequence number存放在全局变量中,出现signal时,handler发送 last grsp存有sequence num给master,如果master多次收到相关信息,另worker重新执行并跳过record