The Design of a Practical System for Fault-Tolerant Virtual Machines
Abstract
性能损失在10%以内,带宽限制在 20Mbit/s以内,能在长距离实现 fault tolerance
Introduction
常用实现方法是primary/backup approach.二者状态要保持一致,保持一致的方法:deterministic state machine.
具体策略:二者开始状态一样,以同样顺序接收同样的输入请求,对于non deterministic ooperation,还要输入额外信息。
使用虚拟机的好处:
- VM可以被当做状态机,其操作都是虚拟化的操作
- VM的hypervisor 对于VM具有绝对的控制权,能够完成input的发送和extra message 的捕获.
BASIC FT DESIGN
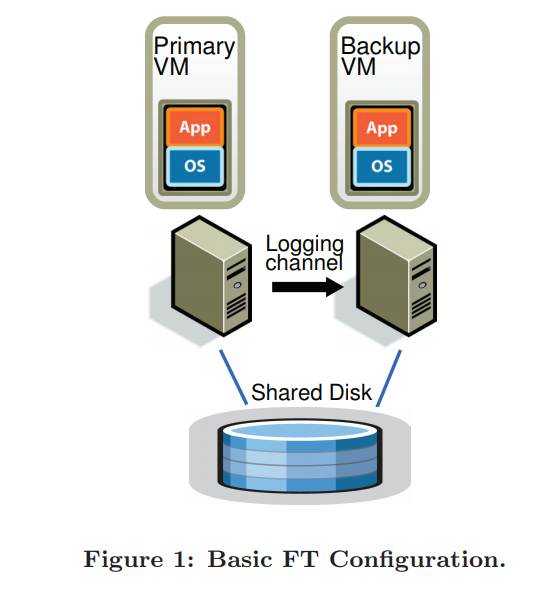
相对于primary, backup放置于另一台physical上,二者步调相同有时间差,(virtual lock step)
virtual disk 放于 shared disk 上
primary唯一在网络上表现存在的server,所有网络和外部的输入都到达primary上,然后primary通过logging channel来实现对backup的传输,传输需要遵循特定的传输协议。backup根据输入同样完成信息的处理,其output被hypervisor drop.
如何检测失败:
primary和backup之间保持combination of heartbeating,同时检测 loggging channel上的traffic,同时保持在任何情况下只有一台机器在跑。
2.1 Deterministic Replay Implementation
面临的问题: 巨大的输入集合,对于non-deterministic operation和event的操作。 面临的挑战:
- 正确的捕获input和non-deterministim
- 正确的应用以上信息于backup
- 不降性能。
解决方法:
和VM execution相关的input 和non-deterministim被Deterministic Implementation记录下来,以log entry stream的形式写到log file中,然后backup通过读取log file中来replay。
####2.2 FT protocol 我们将log entries 通过 log channel 发送到backup上去执行
满足最简单的output requirement:
primary失败后,backup将会继续执行,从外界看保持一致性.
满足output requirement的output rule:
primary不会发送output 到 extern world直到backup收到并且回应了和产出output操作相关的log entry。
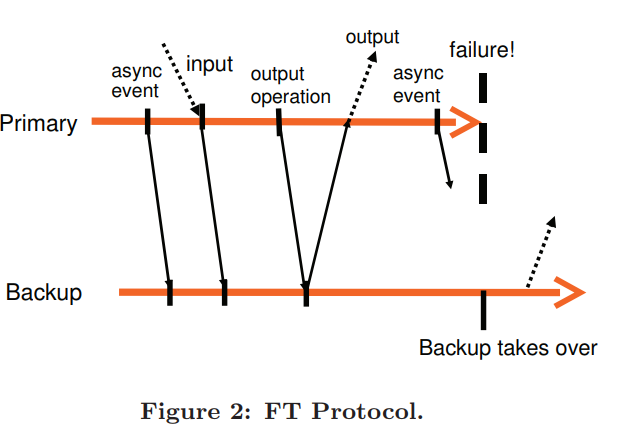 注意我们只是推迟输出,VM依旧可以继续执行。因为os通过异步中断来执行非阻塞的network和disk output。
注意我们只是推迟输出,VM依旧可以继续执行。因为os通过异步中断来执行非阻塞的network和disk output。
由figure2可知,异步的事件,io操作必须先发送到backup上,然后acknowledeged。
####2.3 Detecting and Responding Failure 当backup 失败时,primary go live,离开记录模式,进入普通模式。
当primary失败时,backup进入普通模式,但是有可能有一些log entry 没有执行完,需要先执行完log entry,执行完最后一个log entry之后,离开replaying mode,进入normal mode。并可以产生输出,此时成为新的primary,并广播mac地址,重新处理io。
如何检测failure: - server之间使用 UDP heartbeating.
- 观测log channel的 traffic.
因为regular timer interrupt,log channel会保持规律且并不会因为guset os而停止。
当在heartbeating和traffic直接出现一定长度的timeout时,failure出现。
split brain problem:
有可能因为网络连接的问题会使导致servre出现误判,出现多个server go live的情况。(failure detection的漏洞)
解决方式: shared storage 和 atomic test and set操作。 操作成功 go live,失败 自杀。没有进入shared storage 则努力进入.
3. Pratical implementation of FT
####3.1 Starting and Restarting of FT VMs 问题:如何开启backup并和primary保持一致
问题细节:primary 可在任意状态,能将disrupt降到最低。
解决方法:采用了复制迁移的方法:VMware Sphere
问题二: 具体服务器的选择,redundancy的保持:
任意一台可访问shared storage的集群上的机器。
实现一个维护集群管理和资源的信息。
####3.2 Managing the logging channel server交流的结构如下:
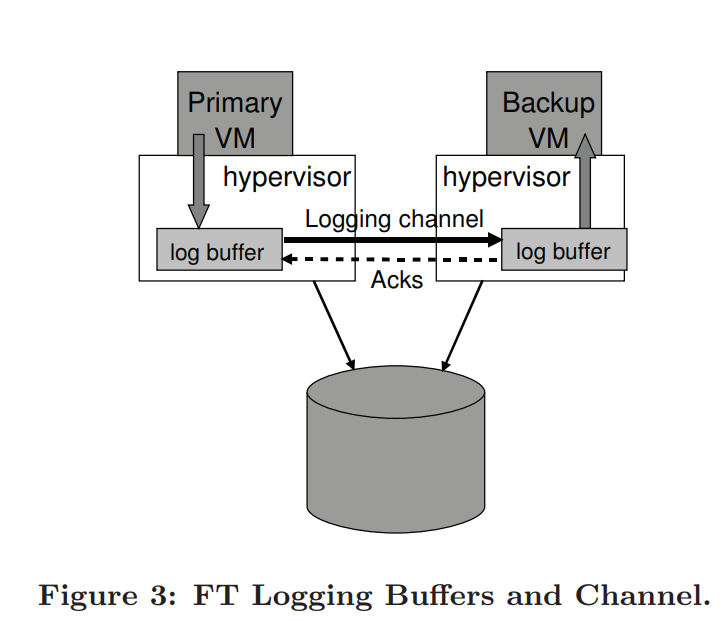
- 如果backup的log buffer空的,他停止并等待下一个log entry的到来,这个停止不会影响系统的执行
- primary的log buffer满的话,他需要停止等待下log entry的使用,会影响系统的执行
2发生原因: backup的server负荷过高,导致cpu和memory的资源侵占,导致primary和backup的步调不一致.
如果二者时间差过大的的话会增大失效备援(failover)时间。
解决方法:通过log channel来完成lag的检测,通过减少cpu的资源完成降低primary执行速度,二者lag在一定范围之内后,在提高primary资源分配,这个问题发生很少
####3.3 Operation on FT VMs 大部分操作都是先经过primary在经过backup,除了VM的迁移。(VMotion),他是indepedent
primary完成迁移需要有断开和重新连接backup的过程
backup也类似,同时,由于迁移是必须在disk IO静默(quiesced)的情况下完成,对于primary,只需要等待物理io完成,对于backup,由于它的操作是不断replay,没有能力使io在任意时间点停止,解决方式:通过log channel请求静默.
####3.4 Implementation Issues for DISK IOs 一些io会导致nondeterminism,例如非阻塞io,并行的,同步的磁盘操作访问磁盘同一位置,或DMA访问内存同一位置,会导致 Io race.解决方式:并行转串行。
第二: 内存访问和磁盘io会race,解决方式:设置page protection temporarily on pages 是disk io 的target。VM去访问相关页时,会触发trap导致parse直到io完成。
上述方法代价较重,采用bounce buffer,disk的读写都经由bounce buffer.
第三:当一个io未完成而primary crash的时候,newly-promoted primary无法确定io是否完成,假设完成,会在后续的操作中出现abort或reset,采取方式:1报错给guest os,not respond well。最终采取方式,go-live过程reissue。 ####3.5 Implementation Issues for Network IO VMware的一些优化基于异步的更新虚拟机的网络设施,但这种异步性如果不保持primary和backup的一致性的话,并不安全。
FT最大的变化是禁止了异步性,将交由guest OS的行为交给了hypervisor。例如对于input packet在buffer中的更新,和将output packet 拉出buffer外。
这种操作会导致network性能的下降,现在讨论性能优化问题:
第一:集群优化:将packet 到一定数量后再处理 第二: 减短发送包的延迟。减少log entry 发送和回应的时间:减少thread context switch的时间。4.Design alternatives
4.1 Shared vs Non-shared
二者区别:
shared disk 只由primary读写,相当于外部对于VM来说,遵循output rule。
non-shared由各自的VM读写,相当于internal message, 不需要遵循output rule
non-shared 应用于primary和backup 无法访问shared的情况,例如二者距离太长。
non-shared的缺点: 显性的同步的保持性
对于split-brain situation,可使用外部的tiebreaker来采用一定算法进行选择。4.2 Executing Disk read on the Backup VM
通常backup不需要disk read,直接通过log channel来传,如果想减少traffic的话,可以让backup执行disk read,
drawback: - backup的read会减慢执行
- extra op需要在read fail的情况下去执行:
- primary succeed 而backup失败的时候backup必须要一直读直到成功
- 如果primary失败的话,将相应内存传输过去。