问题1: 如何简洁的定义语言
将语言定义用层次结构表示
- 用语言字符的集合开始
- 词法结构, 辨别语言中的词
- 语法结构, 辨别语言中的句子
- 语义检查 辨别语言中的意义
定义formal language
俩个对偶的概念:
- Generative approach(grammar 或者 正则表达式)
- Recognition approach(automation) 两种方法可以自行转换
正则表达式
一些字符表,字符的集合。 re的构成规则:
- 空字符
- 任意字符表中的字符
-
r1r2:, r1 r2, r*,括号用来表示优先级和grouping
可以用正则表达式生成一个string. 方法:重写正则表达式知道含有一个句子中只有字符 生成过程中具有不确定性.
另一种抽象方式: 自动机
组成部分:
- 字符表
E - 状态的集合(Q)包含初始(q0)和接受状态(F)
- 不同状态的转换,由字符标识edges: delta QEQ
如何利用自动机接受字符串
- string保有当前状态和和字符串的当前字符
- 以开始状态和字符串中第一个字符为开始
- 在每一步,将当前的字符和对应的转换匹配
- 直到到达字符串的末端或者匹配失败
- 如果结束时处于接受状态,自动机接受string.
NFA vs DFA
DFA: 每一个状态只有一个可能的状态转化 NFA:有可能有很多可能的转换: -. 同一个label有多个装换 -. 标记这空字符串的转换
Generative VS Recognition
- re 给你一种方式去生成语言中所有的字符串
- 自动机给你一种方式去辨认特定的字符串
- 正则和自动机之间的关系 -. Philosophically very different -. thepretically equivalent 4.标准的方法:
- 当定义方法的时候使用 正则
- 使用时利用自动机进行转换
re 向NFA装换
将re转换为不确定状态的自动机,采用递归的方式进行实现.
我们以一个可扩展的NFA用re作为输入边的标记.
然后我们不断的将那些以正则作为标识的边转换为以具体的字符为标识的边的转换.
具体过程如下图所示:
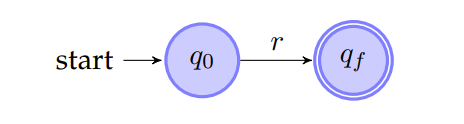
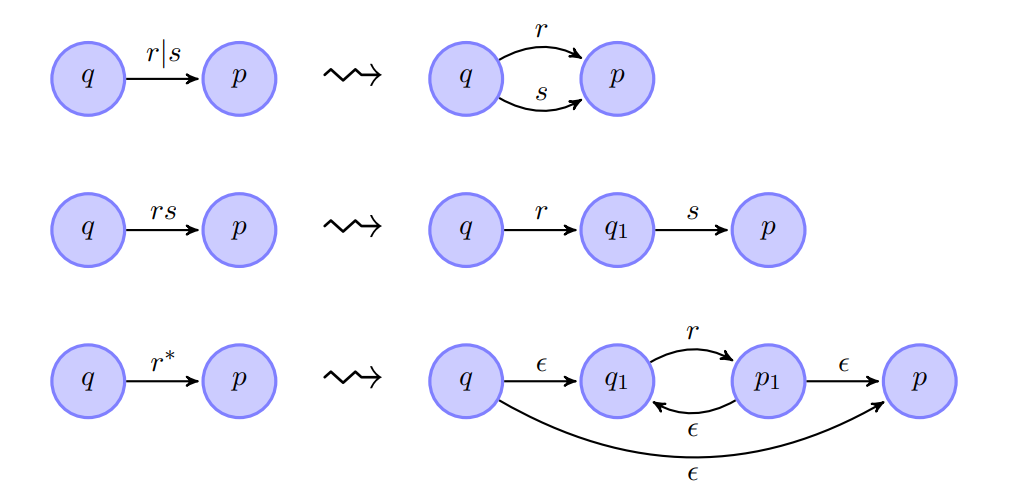
NFA向 DFA转换:
powerest construction:
将单一的状态转化到同一状态中.
先补充一个定义:
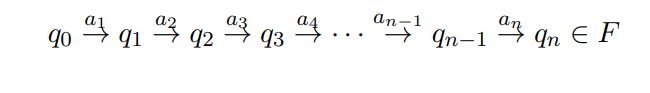 对上述自动机的简洁的表达为
对上述自动机的简洁的表达为 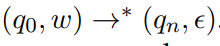 该表达式的含义是q0可以通过变换将字符串内的字符消化,最终到达qn并且没有remaining input to read.
该表达式的含义是q0可以通过变换将字符串内的字符消化,最终到达qn并且没有remaining input to read.