简介
DBMS要达到的俩个核心功能:
- 保护数据
- 在巨大的,分离的使用者访问下,提供正确的,高可用的数据访问
基于此加入俩个核心元件:
concurrency control
在代表使用者的操作在DBMS中是交错进行的,但是从单个user的角度看,数据库状态是一致的
recovery
保证数据库的状态不会因为软件,硬件,或中间件的故障而遭到破坏。
transaction
我们引入transaction的概念来解决这个问题,transaction是一个工作单元,包括许多数据的访问和更新,会abort或者commit,transaction具有四大性质:
1. atomicity
transaction只有俩种状态,要么全部执行完的状态,要么就是没有执行的状态,不会存在执行一半退出,而这一半还会对系统造成影响
2. consistency
让数据保持一致性, 通常让数据满足一系列的性质来完成
3. isolation
一个transaction执行时,处于整个数据库只有它执行的状态的假象,其行为不会受到其他并发的transaction影响
4. Durability
transaction执行的效果并不会因为数据的丢失,破坏而受影响
基本原则
并发控制
serializability
一组交错执行的transaction对数据库产生的影响,输出的结果仿佛这一组transaction按照某一特定顺序进行执行一样,这个性质称为serializability.
我们主要考虑一种serializability: confict serializabilityTransaction schedule
对一个集合中的transaction 执行的schedule规定了由这些transaction执行的操作的偏序。表示了这几个transaction的operation是如何交错的。规定的偏序有俩个:
- 同一个transaction的内的操作顺序不可改变
- 不同transaction涉及的conflict operation的顺序要特定化
什么是conflict operation:不同的operstion针对同一组数据,且有一个operation是写操作
一个序列化的schedule是每一个transaction的操作都按顺序执行,我们可以先构造一个transaction序列化执行的schedule,然后利用schedule的相等性判断某一个concurrent schedule是否具有 serializability.
schedule的相等性,俩个schdelue包含相同的transaction和相同的操作,对于conflict operation的操作顺序要相同,
这样给定一个concurrent schedule我们就可以判断是否serializability
利用有向先序图判断schedule是否serializability
当transactionT1的某个操作在transaction T2某个操作前执行时, T1 -> T2.
通过判断图是否有环来判断schedule是否serializabilityRecovery
coping with failures
recovery subsystem 要对付的几种错误:
- transaction failures 当一个transaction无法提交的时候,它对系统所做的更新都要被消除,这称为transaction rollback
- system failures 当在volatile memory中出现loss时,在crash之前提交的transaction对system的影响不能消除,失败的或者进程中transation需要消除
- media failure 磁盘坏了
buffer management issues
UNDO: 将未完成的transaction的对系统的更新消除
REDO: 重新实例化已经提交的transaction的影响
我们可以通过buffer system将缓存页中的更新推到磁盘上来控制以上操作
STEAL policy: buffer manager 允许未提交的transaction将对最近已提交的transaction改变的数据覆盖并推到磁盘上,称为steal policy,反之称为non-steal policy FORCE policy: buffer manager 在transaction提交之前将transaction涉及到的更新全部推到磁盘上,
STEAL policy 十分需要rollback,因为磁盘上的数据有可能被未完成的transaction改变.
non-FORCE无法保证系统crash的时候磁盘上的数据是最近更新的,导致需要后续的redo操作
NO-STEAL和FORCE会增大操作的可靠性,但会降低系统的灵活性和性能,所以需要综合考虑
logging
log是一个序列化的文件用来保存确切时间点的transaction和系统的状态
在执行undo和redo的过程中需要这些log
log可以记录transaction是否提交或者abort,也可以记录一定时间内的系统的状态称为checkpointing
log可以分为logical log 和physical log, physical log可以记录修改数据的具体位置在page中,还会记录一个数据修改前的值,用来undo,和一个数据修改后的值,用来redo, 利用Log中的数据进行恢复操作如undo和redo是幂等性的,
logical logging用来记录更高层次的东西
例如logical logging会记录一个tuple插入relation中,但不会记录具体的细节例如内存的开辟,Indexing的变化和重新排序等问题,redohe undo需要根据log来自行推断相关操作,操作的时候会比physical 用更少的log,但是由于比较粗粒度,redo 和undo在恢复时会推断出复杂的操作这些操作无法是原子化的操作的时候,例如这部分复杂操作一部分已经被推到磁盘上,导致我们恢复的时候无法确定我们应该从哪恢复
我们妥协一下,将二者融合起来,构造physiological logging,它只记录某一页(将其放置在该页中)内的log,但采取loggical log的记录方式。
write ahead logging (WAL)
write ahead log 保证系统恢复时log拥有足够的信息来执行 STEAL/NO-FORCE缓存管理策略的redo和undo
log存储在memory中,随着系统的crash也会丢失,如何防止这种情况呢?
- 当磁盘上的page被允许覆盖之前时,相关的有关信息更新的log都将被保存在磁盘中,这种情况有利于undo
- 只有所有的log被写入磁盘时该transaction才可被认为提交
Best practice
two-phase locking
我们可以通过locking来实现concurrency,locking有share lock, exclusive lock。但是单纯的lock机制无法保证trasaction的serialization。
我们可以采用two-phase locking,在transation的请求lock的时候不能够释放lock,在释放lock的时候不能够在请求lock
我们采用lock manager 来管理管理lock
还有strict locking,用来防止dirty read, 即释放lock时候一次性全部释放
two-phase locking会导致deadlock,我们可以采取两种技术来应对deadlock, deadlock avoidance 或者deadlock detection
dealock detection 采用俩种方法,第一: timeout,判断transaction是否时长过长来判断是否进入deadlock
第二: 构造有向图,wait-for graph,如果transaction i 需要等待transaction j 释放资源后才能继续执行,则引一条边由i指向j,如果该图中出现环,则出现deadlock。 检测出deadlock后如何消除deadlock的影响呢:
找到deadlock后我们可以通过一定方式选择一个transaction,然后让其回滚以破坏cycle
我们还可以采用deadlock avoidance, 如果一个transaction请求被其他transction持有的lock,则系统选择让一个transaction abortisolation level
transaction 由于采用lock导致的blocking会延迟transaction的响应时间。但某些情况下应用对于并发的一致性的要求并不高,因此我们可以根据locking的级别去定义isolation的level
首先,延伸一下locking的概念来解决幽灵问题,(phantom problem)
幽灵问题的起源来自于当一个transaction1执行类似于聚合满足一个谓词(布尔表达式)的tuple的时候,另一个transaction2突然插入一个满足该谓词的tuple,那么transaction1的执行结果和实际的结果是不一样的,解决方法是将predicate谓词锁住
基于锁定义的isolation定义于读和写操作是否被锁保护,锁是long-duration还是short-duration
级别如下: - READ UNCOMMITED: 允许transaction去读其他未提交transaction写过的数据,在实现中不需要为读设计锁,遭遇的问题有:会读到后来回滚的数据,只有可能读到一部分被更新的数据
- READ commited: transaction只能读取已提交的transaction更新过得数据,读操作有锁,是short-duration,带来问题: 一个transaction的俩次读会读出不同的值,如果俩次读中插入了其他transaction对该值的更改
- REPEATABLE READ 读的锁是long-durable
- SERIALIZABLE: 能坚决幽灵问题,不仅对read上锁,还对read 依赖的predicate也会上锁,而且都是long-duration
Hierarchical locking
lock和conflict是有粒度定义的,granularity可以在tuple层次,也可以在relation层次,还可以在page层次,甚至可以在database层次, 细粒度的lock在将conflict serizable做的很好,但是会频繁的调用lock manager,粗粒度的lock可以减少对lock manager的调用,但是会导致错误的conflict,例如对于有页的lock下的tuple
hierarchical locking引入了除了S, X以外额外的锁模式: IS, IX, SIX分别代表的含义是intensin shared, intension exclusive和shared with intension exclusive
IS(IX)在一个粒度上的锁不会有更高的优先级,但是趋向去去获得更低粒度的锁, SIX是在整个粒度上放一个S锁和一个IX锁
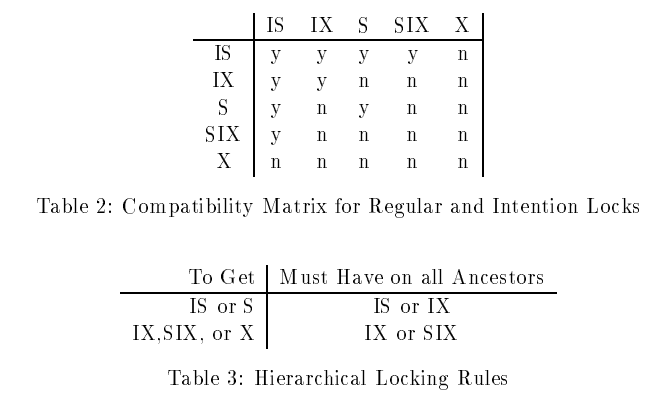 lock escalation: 用来帮助transaction自动的调整相关锁的粒度
lock escalation: 用来帮助transaction自动的调整相关锁的粒度other concurrency control methods
用lock 进行concurrency 进行控制的方式称为pessimistic control.而还有一种叫做optimistic concurrent control,它能够不采用锁的方式进行控制,
为了保证transaction的执行保证serializibility,每个transaction在执行前都要执行validating phase.如果validating phase检测出与其他transaction的冲突,则相关transaction必须abort和restart
和pessimistic control不同的是: optimistic concurrent control 利用restart来保证isolation,这导致了数据争用会影响optimistic concurrent control的性能,因此资源的充足于否决定我们使用何种策略,资源有限制的情况我们采用lock
另一种值得一提的技术是multiversion concurrency control.
Recovery
recovery 被当做最复杂的一个系统,原因有二:
- 要处理db失败的情况,同时要应对数量巨大的数据库的各种情况
- 需要其他部分的支持: concurent system control, buffer management disk management, 和query processing等
Overiew of ARIES
是对WAL的改善。
pageLSN的几个作用: - 决定相关page的更新是否需要重做
- 当系统crash后重启的时候判断从log的哪个节点开始着手
- lsn通常用物理地址实现
算法的基本原理:
基于 repeating history 的REDO paradigm:它对所有的transaction所做的更新都会进行REDO, 包括那些未完成的transaction
repeating history 允许ARIES使用physilogical logging的变体,一个page-oriented REDO + logical undo. page-oriented REDO涉及到对log中指定的page进行redo操作,logical undo 涉及到表示一个用来undo一个更新的操作不需要严格是原来操作的翻转
logical UNDO的好处: - 更细粒度的locking和更高并发的索引管理
T1会更新在某个页上的index entry, 但是在T1没有完成的时候,T2突然改变了该index所在的页,此时如果undo T1,用的是physical undo的话,会导致该操作错误的在页1上处理,而如果采用logical UNDO的话,该操作会首先根据索引结构找到相关索引的确切位置,再进行操作。
page oriented undo不需要采用logical的原因,利用repeating history 的redo paradigm机制,所有改变index存储页的操作都会被记录log之中,对相关indexlog操作之前,只需要redo就可以了
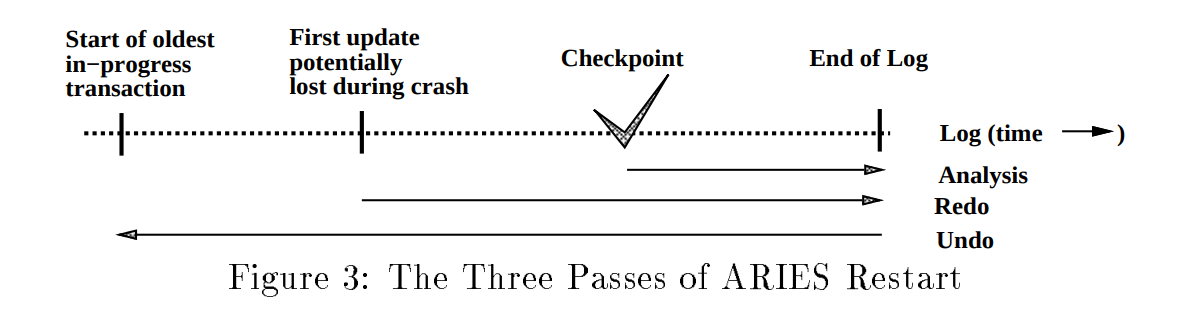
ARIES recovery 采用三步走算法,具体过程如图所示:
 俩个重要的数据结构:
俩个重要的数据结构:
transaction table和dirty page table
transaction table中包含每个正在运行的transaction 的相关信息,其中包含lastLSN,是transaction所写的最后一个log的标号,dirty page table包含所有dirty page的信息,dirty page是指相应更新没有同步到磁盘上的page
dirty page table中包含recoveryLSN,代表重启时最早需要被redo的log的lsn,每一个log record 都有一个field叫做prevLSN,存储上一个log 的LSN
checkpoint 是在获取时包含transaction table和dirty pagetable的相关信息,它具有有效性因为checkpoint不需要停止操作和 flush database page,但是其有效性限制在dirty page最早的recovery LSN上,所以需要另一个线程执行在后端执行flush的操作
现在我们分别考虑三大步骤。Analysis
- 判断从哪个log开始执行redo
- 判断在crash的时候那些page是dirty的
- 判断那些transaction在crash的时候没有执行完需要undo
在analysis scan的过程中,重构 transaction table和dirty page table
对于transaction table,当在scan过程中遇到有关于某个transaction的log不在transaction table中,将该transaction加入transaction table, 如果遇到一个log 有关于某个transation commit或者 abort的时候,将该transaction移除transaction table
当遇到有关某个page更新的log没有被记录在dirt page table中的时候,相关page被记录在dirty page table中,该log的LSN被记录在recovery LSN中,该table中最早的recovery LSN是redo的起点
Redo
为了redo 一次更新,logged action被重新应用,x相关页的page LSN被设置为redo log的lsn
如何判断一个log 需要redo: - 如果被影响的page不在dirty page table中,则update不需要redo
- 如果page在dirty page table中,但table中的recovery lsn要比该record的lsn大,则该log不需要redo.
- 否则的话,需要检查page中的page LSN,如果page LSN大于等于被检查的log的 lsn,则不需要redo,否则需要redo
Undo
undo 引入了一个类型的log record 称为compensation log record,用来减少无用undo的次数,它包含一个UndoNextLsn的参数,执行到该log的时候,直接跳到相关log 执行undo
####本文主要引用自《Concurrency Control and Recovery》这篇论文