Distributed OLTP Databases
1. parellel vs distributed
并行数据节点物理距离接近, 节点之间用高速的局域网连接,交流代价非常小。
分布式数据库物理距离遥远,节点直接用公用网络连接,通信代价昂贵且造成问题不可忽略。
2. 系统体系结构
体系结构指出了cpu可以直接访问的共享资源,这影响了cpu之间是如何协作的,并且影响了数据库是如何存储检索对象的。
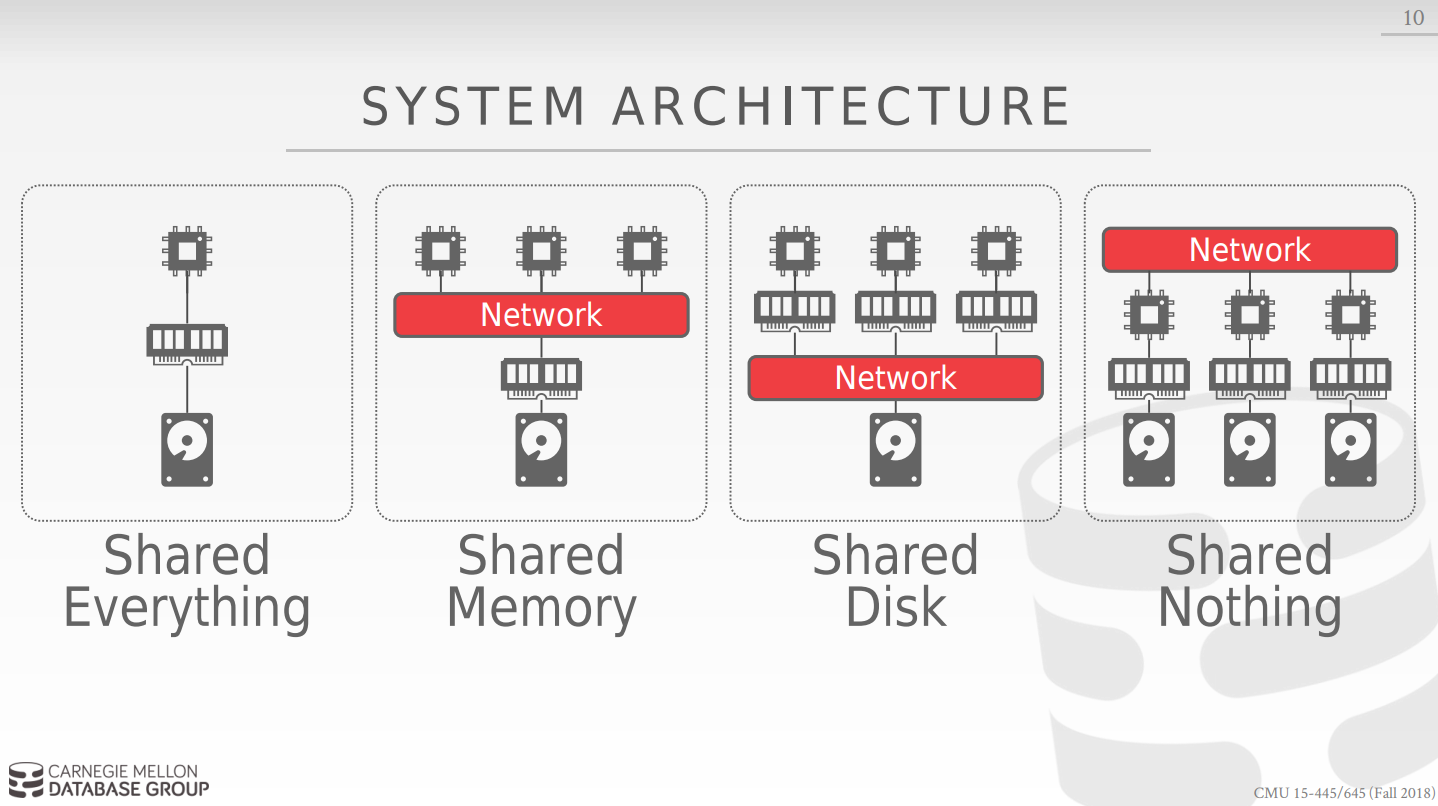
- Shared memory 来考虑shared memory这种情况,不同的cpu共享一个内存,他们利用内存的fast inerconnect进行进行交流,而这更多在操作系统级别被提供该功能,进程,线程模型。由于他们共享一个内存,所以每一个cpu都对所有内存中的数据结构有一个全局的认识,同时,由于isolation(隔离性),每个cpu都只认为自己是唯一的,这样当不同cpu的进程访问共享内存的同一个位置时,会造成问题,所以该类型的分布式数据库必须每个cpu正在运行的实例都必须清楚其他正在运行的实例。(实际过程中该模型很少采用)。
- Shared Disk 所有的cpu可以访问同一个逻辑磁盘,同时每一个cpu都有一个私有的内存。这样做的好处,后端的逻辑磁盘可以为一个大型的文件存储系统,而前端每一个cpu代表的节点是无状态的,因为其相关处理的数据不会存储在该节点,而是会统一的存储在磁盘中,这样我们可以前后端分离,可以扩大cpu node的规模而不用担心磁盘。扩大存储容量而不担心前面的node.
要考虑的问题: 当一个节点更新磁盘的内容时,他必须通知其他有可能访问该page的节点相关信息。 - Shared Nothing 每一个节点都有独立的cpu,私有的内存和磁盘,每一个节点都需要利用网络交流,这样可以很容易的增加数据库的容量,但同时很难维护数据库的一致性,同时数据库加入新的节点后要注意对数据进行shuffle.
3. 设计问题
要考虑的问题:
应用如何找到数据?
面对分布式的数据如何执行query
数据库系统如何保持正确性 -
同构节点 vs 异构节点 同构节点: 集群中的每个节点都执行同样的任务:即一个数据库要求的任务,好处,当一个节点坏掉时候可以转到另一个节点继续执行任务,节点之间交流代价较少. 异构节点: 集群中不同的节点执行不同的任务,通过不同节点之间的通讯来完成任务,好处,你可以提高某一个功能的容量通过增加该类型的节点。 节点设计中比较优秀的设计:
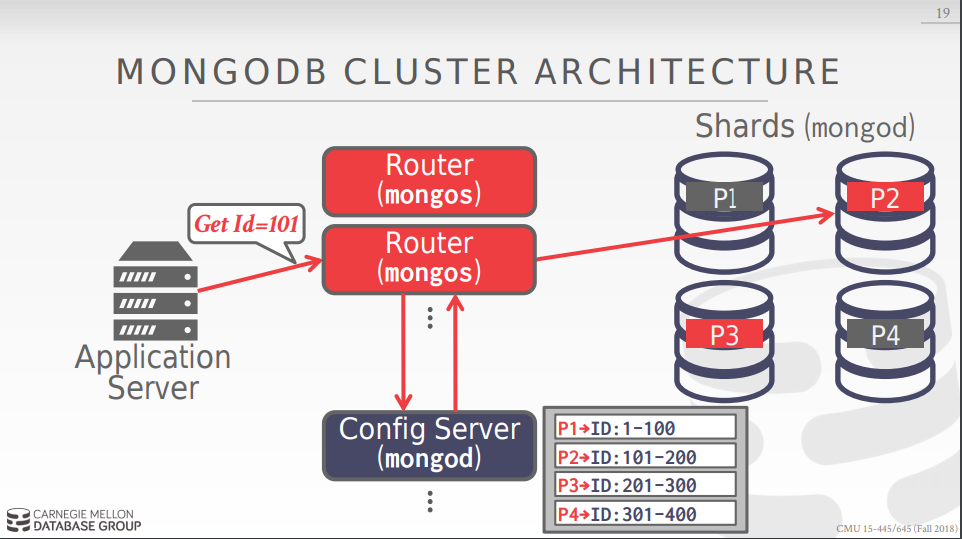
mongoDB中router和config server的设计,如图:
- 数据库的切分 对不同资源的数据库进行切分如磁盘,节点,处理器。
最基本的切分方法:
每个节点存且仅存一张表,具体如图:
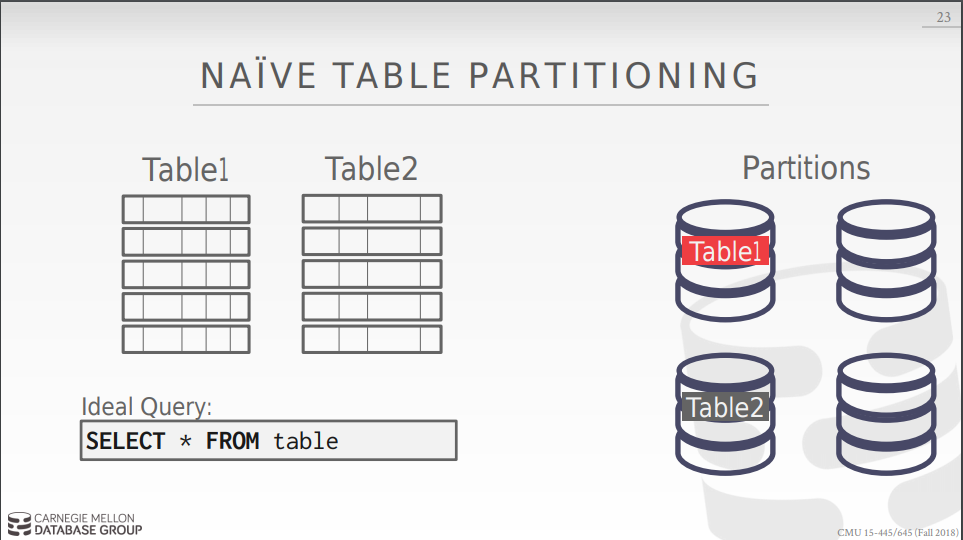 存在问题:没有办法scability,原因如下:
存在问题:没有办法scability,原因如下:
存在某一个table的node有可能会成为hotspot,导致出现问题。 在进行join的时候,你会对俩个表整体进行处理,这样做的代价很高,所以一般每个Node会存储一个table的subset. 将table切分为subset的方式:
选择表中的某一列,将其作为partition key,利用一些partiton的方式(hash partition 或者 rang partition)将数据库进行分割,使其均匀的分布在集群中,来保证其Load,size, usage的均匀.
hash parttition 和range patition各有各的优点, range partiton设计到对range的query的时候更适合。hash partition则可在处理连续数字将其分布在不同partition上有优势.
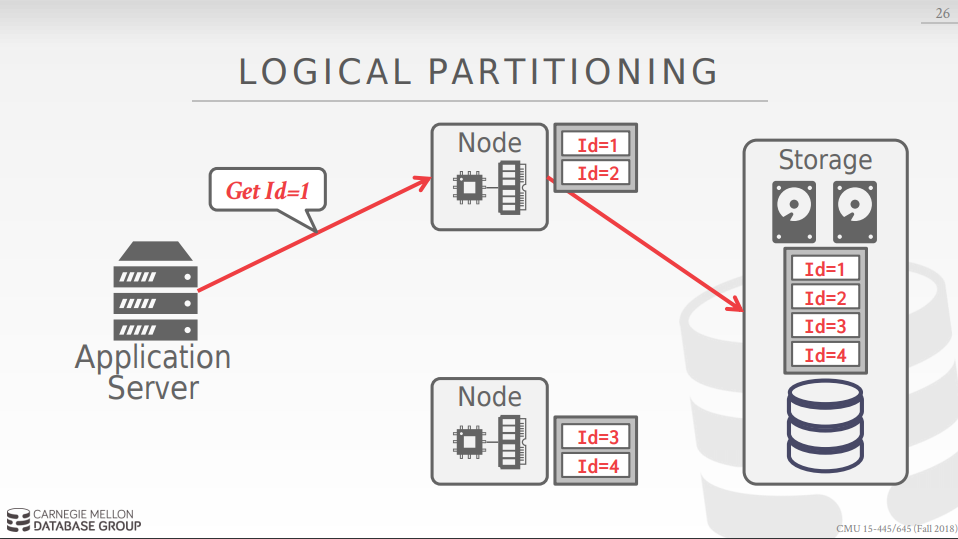 每个nodes 都是无状态的,只有memory和cpu,因此通常每个节点专门负责一部分数据的存储(在share disk上)和读取.
每个nodes 都是无状态的,只有memory和cpu,因此通常每个节点专门负责一部分数据的存储(在share disk上)和读取.
physical partition:
transaction coordination
当dbms执行multi-operation 或者 distributed txn时我们需要去组织其执行。
有俩种类型:
第一种是centralized ,第二种是decentralized.
中心化的有俩种,第一种是采用coordinator,将处理app发过的lock request 和commit request.
第二种是采用middleware,处理app发过的query request和commit request,更为普遍.
去中心化的方式如下: app向任意一个节点发送请求来开展txn,该节点决定哪些节点会被该txn用到,为其上锁,然后app向对应节点发送query request.app最开始发送begin request的节点发送commit request,然后该节点和其他节点交流,最终完成任务。
Distributed concurrrency control
相比于以前的算法: 该算法要考虑的问题有:
- replication
- network communication overhead
- Node failures
- 全局的clock的统一.
我们用distributed 2P来分析该问题:
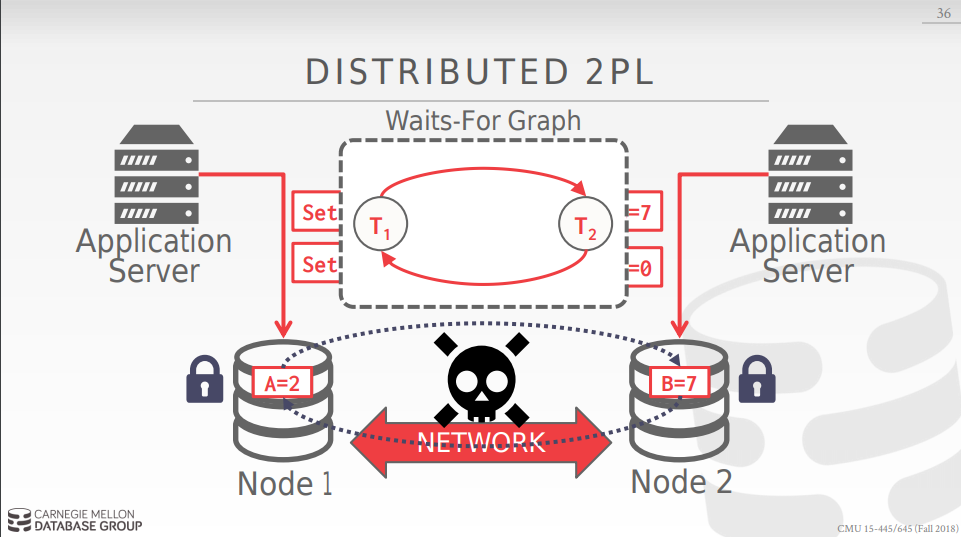 node 1对应的server要更新a = 2, b= 7, node 2处的server要更新b = 7, a = 0,所以node1处的server要对node1 和node2上锁,同理node2,但是由于二者是通过网络来完成该任务的,没有全局的lock table,就会造成事实的死锁,但二者不自知,如果是centralized的方式这个问题很好解决因为有全局信息,但是相关全局掌控的server会造成hotspot,而去中心化的方式可以很好的scability,但却缺乏global view.
node 1对应的server要更新a = 2, b= 7, node 2处的server要更新b = 7, a = 0,所以node1处的server要对node1 和node2上锁,同理node2,但是由于二者是通过网络来完成该任务的,没有全局的lock table,就会造成事实的死锁,但二者不自知,如果是centralized的方式这个问题很好解决因为有全局信息,但是相关全局掌控的server会造成hotspot,而去中心化的方式可以很好的scability,但却缺乏global view.
decentralized transaction
以下为decentralized coordinator的工作方式: 首先选定集群中的一个base node,对他发起 begin request 请求, 然后根据反馈信息决定向集群中的节点发送query request 请求,最后向base node发送commit request, base node向其他节点询问后决定是否commit.
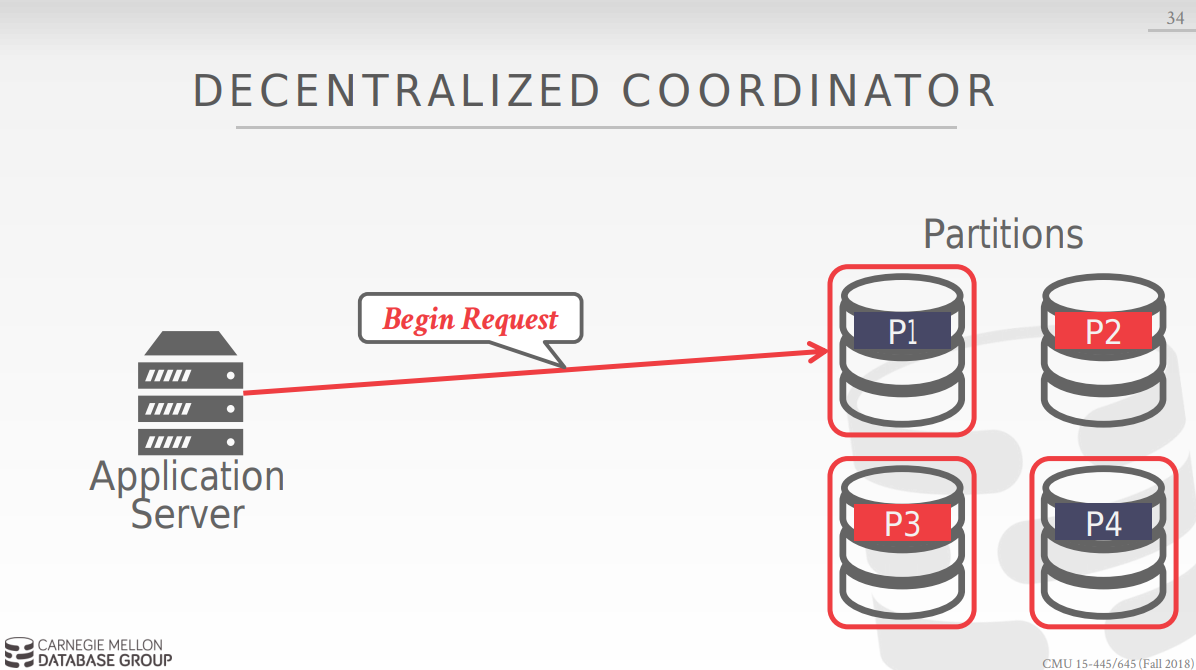
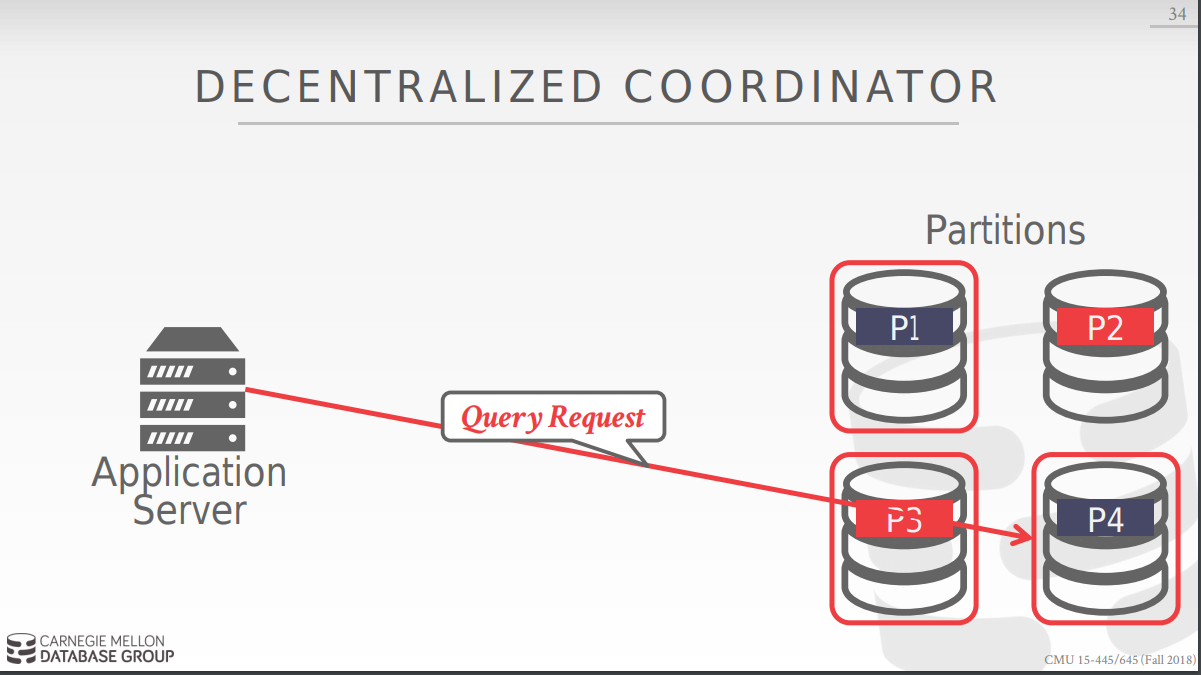
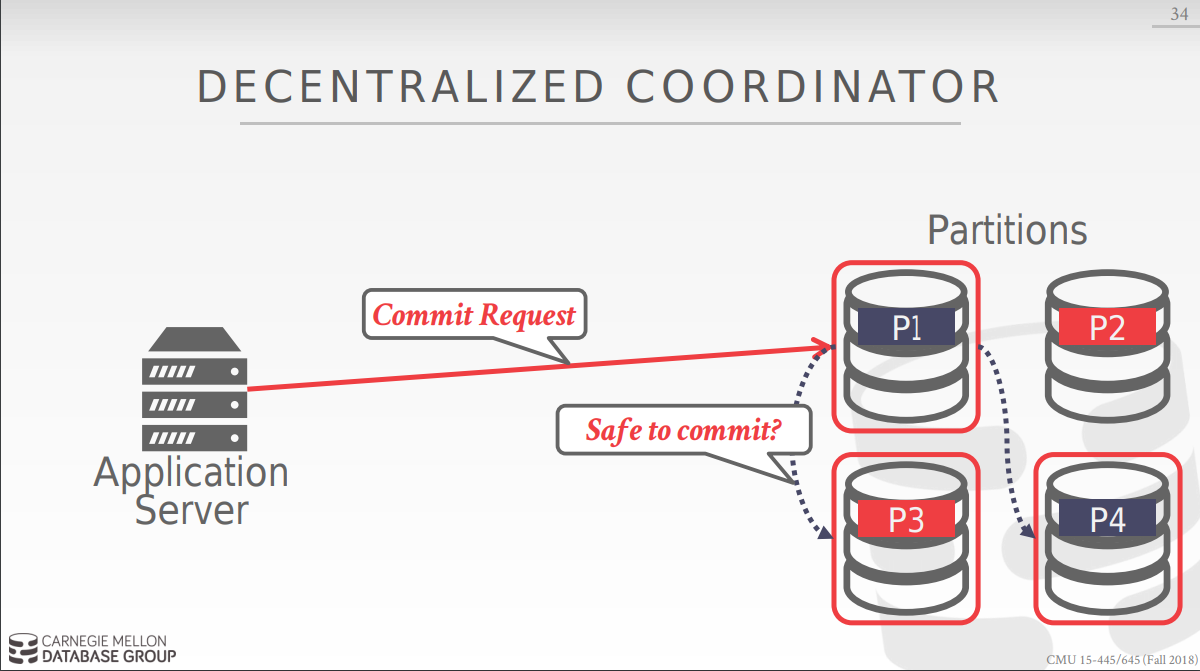
问题: 在分布式系统中网络的速度是必须要考虑的重要问题:
我们需要考虑的情况有 如果某node连接不上,如果相关信息由于网络原因出现的晚或者我们等不及所有node都发回同意的信息我们该怎么办?
Atomic commit protocol
当一个multi node txn完成的时候,DBMS需要去询问所有涉及到的节点是否可以安全提交.
不同的协议: two-phase commit, paxos, raft, zab等等.
首先看two phase commit:
two phase commit 分为两步,第一步 是prepare,向涉及到的节点询问是否可以commit,第一个过程成功后,进入第二个过程commit, base node向所有节点发送可以commit的信息后,所有node commit并acknowledge,success.如下图所示:
以下是流程图:
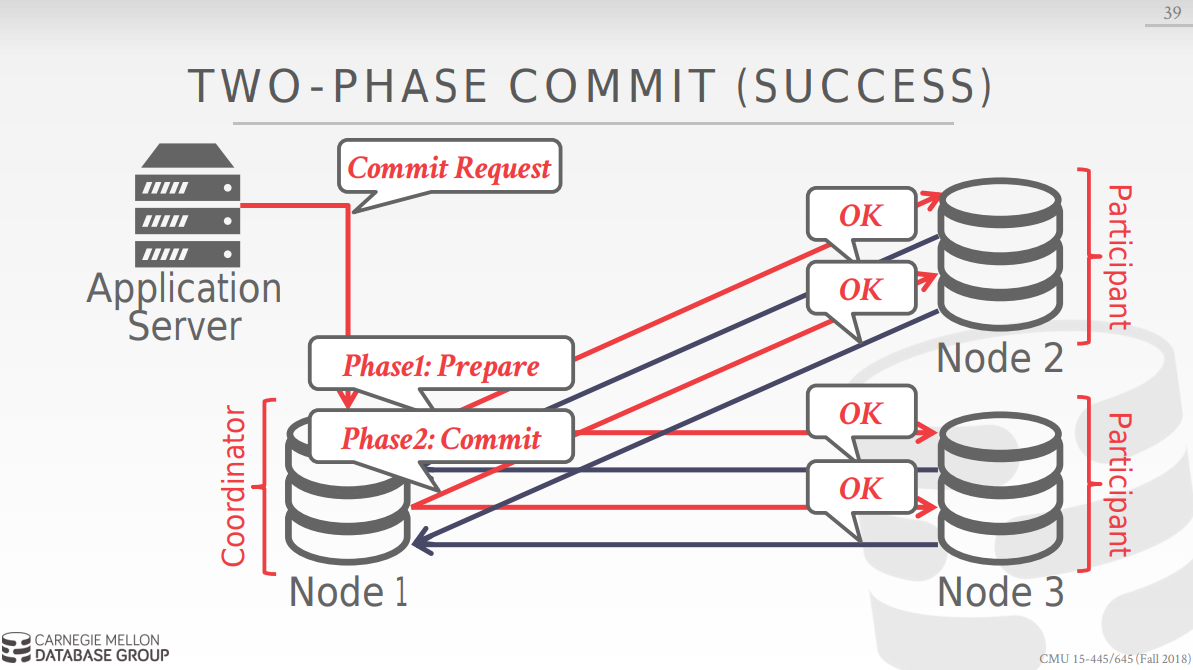
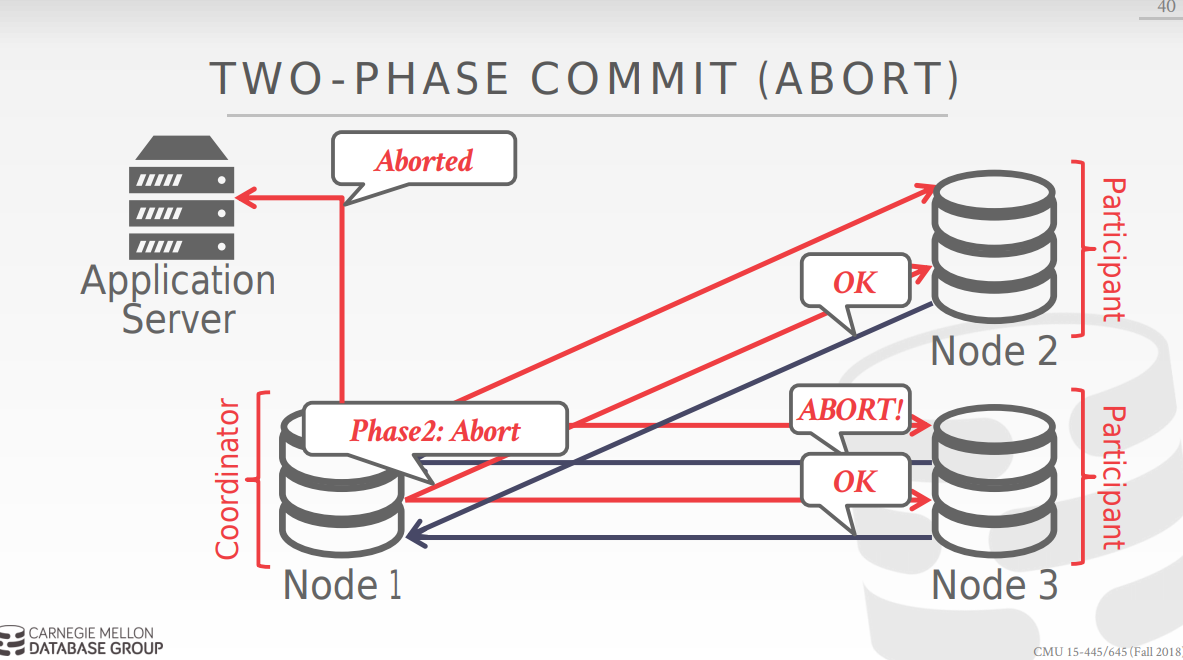 2 pc的优化方式:
2 pc的优化方式:
第一种是early prepare voting :
当query发送到最后一个node时候,可以顺带的把各种voting信息返回回来提高效率。 第二种是early acknownledgement after prepare:
如果所有的nodes同意去commit 一个txn,base node可以向client发送txn成功的请求,在commit phase 完成之前.